AGI只差最后一步了

从“太危险”到上线:Anthropic给Mythos加上了安全锁
昨天晚上,Anthropic终于正式上线了此前因“过于强大、担心被滥用”而拒绝公开的Mythos模型。这个模型曾被内部称为“太危险不能公开”,如今之所以敢放出来,是因为团队给它附加了一层安全分类器。这意味着AGI在迈向通用能力的路上,安全护栏的重要性已经上升到“最后一公里”的核心环节——一个能解国际数学奥赛题的系统,同样需要被严格约束在可控范围内。Anthropic的举动表明:AGI的最终形态不能只堆砌能力,还必须嵌入可靠的安全机制。
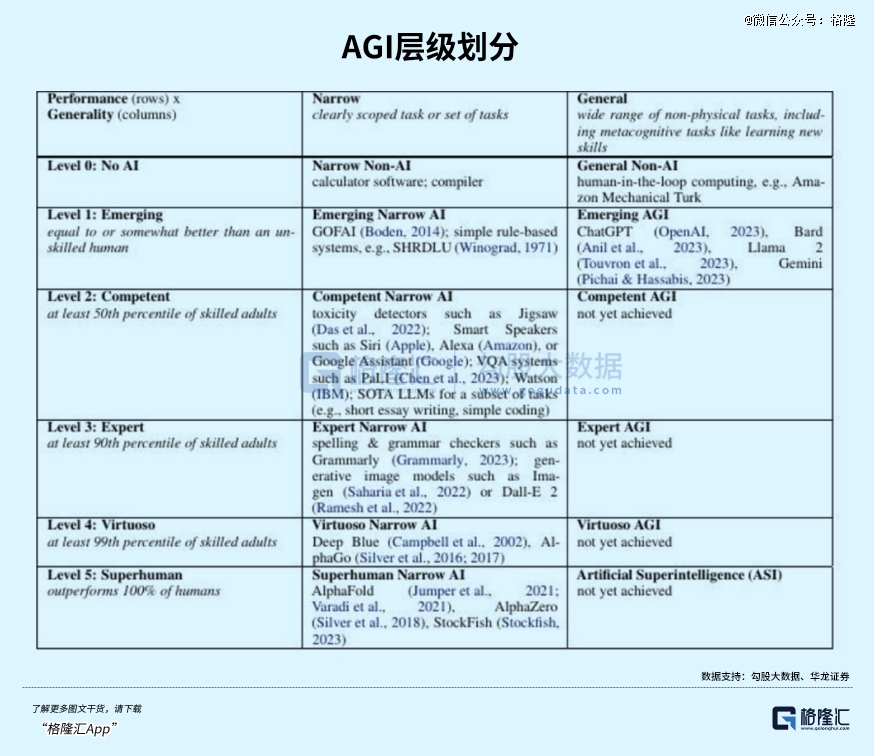
DeepMind CEO:AGI拼图只差最后几块,但大模型还在犯低级错误
Google DeepMind CEO直言AGI“已在正确路上”,但缺“最后一两块拼图”。他明确指出当前大模型存在一个诡异的短板:同一个模型能解国际数学奥林匹克金牌级别的难题,换个问法却在小学数学题上栽跟头。更致命的是,模型“不知道自己错了,也不知道怎么推翻或纠正自己”——做错就一路错下去,或者换个方向再撞一次,像新手棋手反复掉进同一个陷阱。这暴露出大规模预训练、RLHF和思维链等技术虽然搭建了基础框架,但在可靠推理和错误修正上仍远远不够。AGI的“最后一块拼图”,正是让系统学会自我质疑与动态纠正。
我们已走到AGI 2.5:持续学习才是最后那道坎
一个新的研究框架给出明确判断:AGI之路已经走完一半,现在正处于从第二阶段“推理者”向第三阶段“智能体”过渡的中间态,即AGI 2.5。剩下的过程“主要需要正常的研究和工程”,但最大的挑战是持续学习——模型必须能在与真实世界交互中不断更新知识,而不只是靠静态数据集死记硬背。引用达里奥·阿莫代伊的观点,这个问题的解决将决定AGI能否从“实验室玩具”变成真正的自主系统。2.5阶段的定位说明:我们已经跨过了基础推理门槛,但距离能自主规划、执行并自我迭代的智能体,还有一段关键的工程化路程。
颠覆认知:AGI的秘密不在更大模型,而在推理之网
一篇最新论文的核心结论彻底改变了人们对AGI路径的传统认知:AGI不会来自更大的模式之海,而是来自如何组织这些模式以形成可靠推理的“网、诱饵、过滤器和记忆机制”。换句话说,未来突破点并非无上限扩大模型参数量,而是设计一套架构——让模型能够从海量信号中筛选有效信息、过滤噪声、建立逻辑链条,并在长程任务中保留关键记忆。这就像用记事本写了一百万字的笔记,如果不分类、不打标签、不建立索引,那本笔记毫无用处。AGI的“最后一两步”正是把混乱的知识模块,编织成一个能主动推理、自我校验的智能网络。