从「片段生成」到「长视频漫游」:OmniRoam探索轨迹可控的长视频生成新范式

近年来,视频生成技术在AI领域取得了显著进展,但仍面临两大核心挑战:一是生成长时序视频时的空间一致性难以保障;二是对场景轨迹的控制能力较弱。为此,OmniRoam应运而生,它通过一种“从片段生成到长视频漫游”的全新范式,引入了全球到局部的两阶段生成策略,从而实现更加沉浸和可控的长视频生成体验。
OmniRoam的技术背景
- 传统视频生成模型在处理长时间序列时容易出现场景断裂或逻辑混乱。
- 透视视频生成模型虽然在局部场景控制上有一定优势,但在全景建模和时序连贯性方面存在明显短板。
- OmniRoam利用全景表征的特性,解决了长期时空一致性的问题,为长视频生成提供新思路。
框架的核心设计
OmniRoam框架采用两阶段设计:
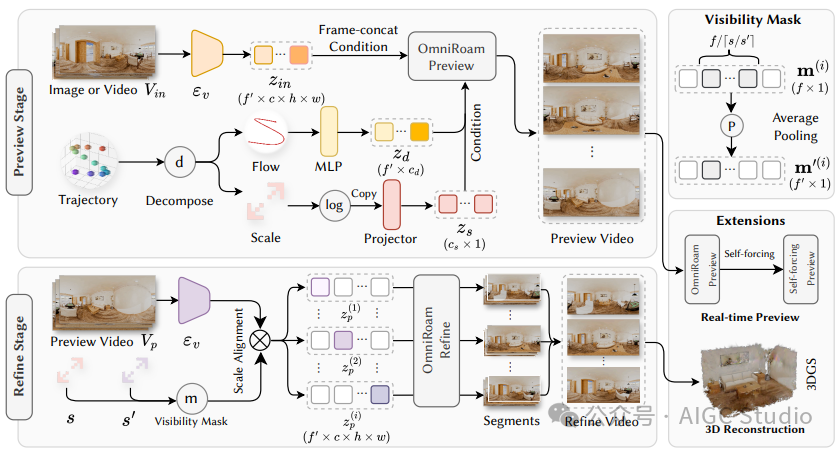
第一阶段:轨迹控制的场景预览
- 基于输入图像或视频片段,快速生成全景场景的概览。
- 通过轨迹控制模块,引导生成视频的整体运动路径与场景结构。
- 利用全景图像的广覆盖性,确保初始场景的逻辑连贯。
第二阶段:时序扩展与空间超分优化
- 在预览基础上进行视频的时序扩展,延长生成内容的时间长度。
- 同步进行空间超分辨率处理,提升每一帧的视觉质量。
- 保持全局一致性的同时,细化局部动作和细节,提升沉浸感。
关键技术优势
- 全景表征能力:每帧图像覆盖更大场景范围,有助于维持长时间的视觉一致性。
- 轨迹可控性:用户可通过指定轨迹,引导视频生成的方向和路径。
- 高质量输出:两阶段优化策略支持高分辨率、长时间的视频生成,突破传统方法的瓶颈。
可能的应用与影响
- 虚拟现实与沉浸式内容创作:OmniRoam为VR视频生成提供了更加自然和可控的生成方式。
- 影视与游戏场景生成:可用于快速构建复杂场景下的动态环境,降低人工建模成本。
- AI辅助叙事与交互式视频生成:轨迹控制能力为交互式视频生成与AI叙事提供了新的可能性。
展望未来
OmniRoam代表了视频生成领域从“片段生成”向“长序列可控漫游”演进的新方向。未来,该框架有望在多模态输入(如文本+轨迹)、多场景融合、以及实时交互生成方面进一步拓展,为AI驱动的内容创作提供更强的表达力与灵活性。