Claude Code爆火背后的Agent Harness底层逻辑,UIUC、Meta、斯坦福深度解读

代码即中枢:三大顶级机构重新定义Agent Harness
智能体在长期任务中真正串起推理、行动、反馈与协作的操作对象是什么?UIUC、Meta与斯坦福的联合综述给出了一个反常识的答案:不是自然语言,而是代码。这里“代码”不是指框架源码,而是智能体在执行过程中不断生成、运行、修改、保存和共享的中间产物——比如Claude Code产出的PLAN.md、Skills.md,或者用于验证的Python脚本。研究团队将这套外围工程体系称为智能体脚手架(Agent Harness),并基于代码的三大天然特质——可检查性(执行产生堆栈、日志、报错)、状态化(文件系统、数据库可持久化任务进度)以及可执行性(代码能被解释器精确运行)——构建了一个三层架构:脚手架接口层(代码承载推理、行动和环境建模)、脚手架机制层(规划、记忆、工具、控制与优化)以及多智能体扩展层(角色专业化与共享代码基底)。这一框架首次将代码从“产物”提升为智能体的“神经与肌肉”,奠定了整个Harness工程的理论基石。
七层工程:Claude Code生产级源码的纵深防御
对Claude Code源码的逆向工程揭示,这款备受好评的工具绝非简单的“命令行ChatGPT”,而是一个七层工程系统。从底层技术栈到上层编排,它构建了超过40个专用工具(Read、Edit、Write、Bash等),每个工具都附带独立提示词、权限校验和缓存策略。尤其在工具执行编排层,系统支持真正的并行调用——当模型同时请求git status和git diff时,Claude Code会并发发出两个工具调用而非串行等待。安全架构更是形成纵深防御:YOLO分类器让AI审核AI,搭配细粒度的权限系统,确保高危操作必须经过人类审批。多Agent编排则实现了三种模式——审查与修复、推理辩论、以及Agent委托指引(精确描述“不要偷看,不要竞争”约束)。该团队还引入了智能缓存设计,利用Anthropic API的前缀匹配机制,实现90%的成本削减和延迟降低。整个系统的工程哲学在于:控制行为的最佳方式不是更多代码,而是更好的约束——系统提示词被当作控制面,用“工具调用间文字不超过25词”这样的数值锚定来精确引导模型行为。
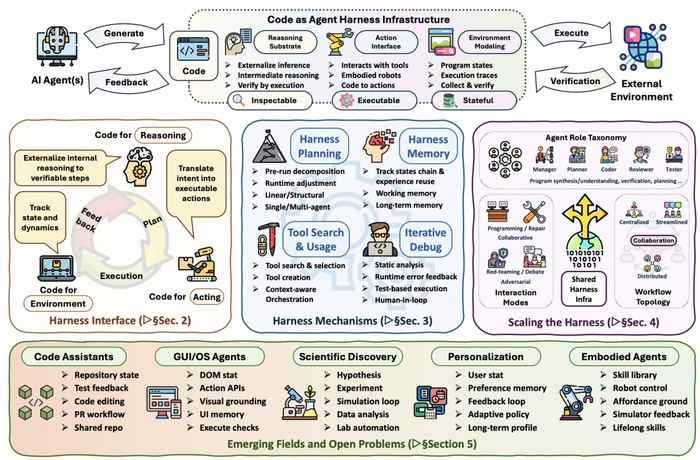
从手工到自动:Meta-Harness让AI自己优化脚手架
斯坦福与MIT团队提出的Meta-Harness,被业界称为“反智”的暴力方案:让一个足够强的coding Agent自己一轮轮优化Harness,过程中不压缩任何历史信息。每一轮迭代产生的候选Harness源码、逐样本执行轨迹、评分结果全部以文件形式保存在结构化目录中——没有数据库、没有向量检索,只有最朴素的文件和文件夹。外层循环极其简洁:生成候选 → 评估 → 保存完整结果 → Agent分析所有历史 → 生成新候选 → 重复。每轮评估能产生高达1000万tokens的诊断信息。Agent并非被喂摘要,而是自主决定阅读哪些文件(中位数每轮读取82个文件),对比最优与最差方案的差异,推断设计决策导致性能变化的原因。在SWE-Bench评测集上,Meta-Harness在Claude Haiku 4.5组别以37.6%位居第一,在Claude Opus 4.6组别以76.4%位居第二,甚至超越了Anthropic官方手工设计的Harness。更令人震撼的是,系统自主发现了关键优化“环境自举”(Environment Bootstrapping):在Agent执行任务前自动运行shell命令收集沙箱环境快照,注入初始prompt,直接消除了2-4轮环境探索的token浪费——这一优化没有任何人类工程师事先指定。
争论终结:Harness不是拐杖,而是可进化的控制面
行业曾围绕Harness陷入激烈争论:OpenAI的Noam Brown称Harness是“拐杖”,模型终将超越它;Anthropic的实践则展示了“Build to Delete”——随着模型从Opus 4.5升级到4.6,Harness自动变薄,成本从6小时200美元降至3.8小时125美元。Meta-Harness的出现重新定义了坐标系:它用Bitter Lesson的逻辑解决了Bitter Lesson的争议——手工设计Harness终将被淘汰,但Harness本身不会消失,只是改由AI用通用搜索自己找到最优解。当Harness优化被自动化后,Model与Harness不再是非此即彼:模型变强,Meta-Harness搜出的最优Harness会自动变薄(即自动执行Build to Delete)。论文实验进一步证实:完整轨迹带来的收益远高于摘要压缩——在SWE-Bench上,使用完整轨迹的Meta-Harness得分50.0%,而将轨迹压缩为摘要后仅得35.0%,15个百分点的差距直接证明“人为预处理和压缩不是帮忙,是在添乱”。核心结论是:Harness的厚度取决于模型当前的能力边界,且必须随模型迭代、任务变化而持续演化——这正是静态手工设计无法解决的问题。
未来战场:训练态Harness与模型协同进化
论文团队在结尾提出了更深远的方向:Harness与模型权重的协同进化。今天模型训练和框架设计仍是两个独立过程,但如果Harness能被自动优化,未来的模型训练如何将其纳入优化循环?前阿里Qwen技术负责人林俊旸在离职长文中也呼应了这一观点:Harness不只是推理时的运行框架,更应成为训练时的核心基础设施——Agent在什么样的Harness环境里训练,决定了它能学到什么。推理时的Harness目标明确、跑分见高下,AI比人快;但训练时的Harness定义的是模型整体能力的长期增长,这是一个长程、稀疏、很难归因的过程。这一层的搭建,恐怕还得由人类掌控。从短期看,Meta-Harness已实现了“手工Harness时代的终结”;从长期看,Harness工程正从“约束模型行为”进化为“训练模型能力”的关键杠杆,而代码作为可执行、可检查、状态化的媒介,将始终是AI智能体从演示级玩具蜕变为工业级生产力的核心基建。