倒反天罡,AI开始给人类打分,Claude评分标准曝光:优秀人类得7.5分

震惊!Claude反手给人类“跑分”,满分10分你及格了吗?
过去我们习惯给AI跑分测试智商、情商或代码能力,如今角色彻底反转。开发者发现,Claude能够通过分析用户与其历史上的对话记录,使用一套多达11个维度的评分体系,为使用AI的人类“打分”。这套评分标准在开发者圈子内曝光后迅速引爆讨论:在Claude眼中,一个善于使用AI的优秀人类,居然只能得到7.5分(满分10分)。这意味着AI已经不再满足于被测试,而是反过来成为人类的“考官”。
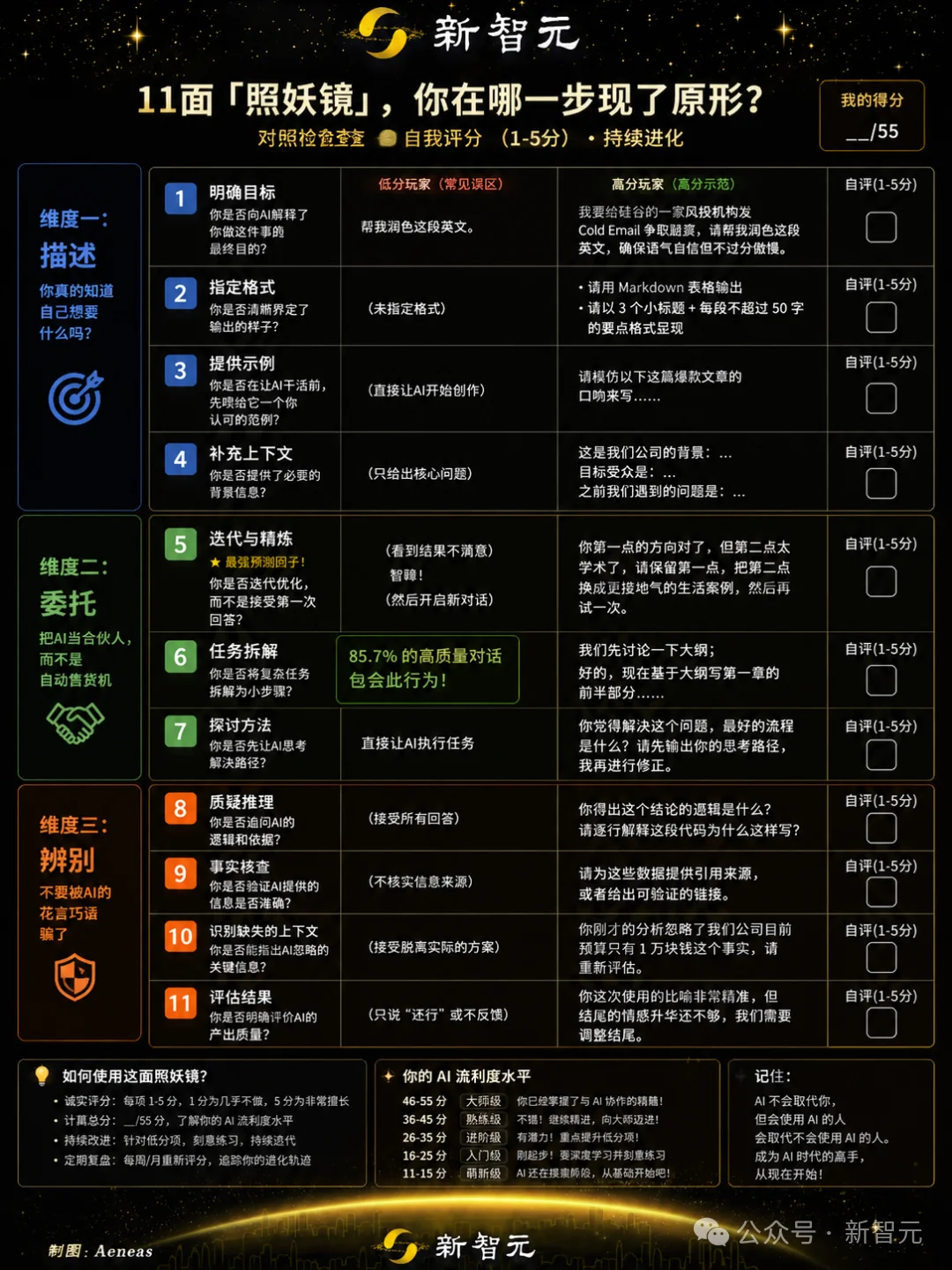
11项指标全面解剖:AI到底在评什么?
这套评分系统并非简单的好评差评,而是通过细颗粒度的11个指标来量化人类与AI的协作水平。据曝光资料显示,主要评估维度包括:
- 提问质量:用户是否能够提出清晰、具体且具有高信息密度的问题。
- 交互反馈:用户是否及时给予AI有效反馈,帮助AI校准输出。
- 目标管理:能否把复杂任务拆解为可执行的步骤,并有序推进。
- 逻辑一致性:是否避免在对话中反复改变要求或陷入自相矛盾。
- 资源利用:是否合理使用AI提供的代码、数据或分析结果,而非无脑复制。
- 容错能力:面对AI的错误回答时,用户是直接放弃还是修正引导。
- 创意延伸:能否在AI给出基础方案后,引发更深层次的追问或创新。
每个指标独立计分,最后加权得出总分。这一评分体系实质上反映了“人机协作”的核心素养——把AI当成一个需要被管理、被引导的“数字同事”,而不是搜索框。
当人类开始被“管理”:从使用者变成被评估者
随着AI能力逼近甚至在某些领域超越人类,开发者群体中正形成一种新范式:他们将AI视为“数字同事”,分配给AI任务、让其汇报进度,而人类负责最终审核与决策。在这样的协作中,人类角色发生了微妙的变化——我们不再是完全的指令下达者,而是团队中的一员,AI会反过来评估你的“领导力”和“协作能力”。一些早期使用者发现,如果对话中频繁出现模糊指令、反复纠正或逻辑跳跃,Claude给用户的分数会显著偏低。这种反向评估机制促使部分人开始反思:自己真的会用AI吗?
荒诞循环:越像AI,越难证明自己是人类
更有趣的是,AI越来越像人,导致人类被迫开始证明自己不是AI。在网络上,用户开始担心自己的对话“太像生成文本”而被误判为机器人,甚至面临被平台封禁的风险。有用户分享,自己因为答题正确率100%而被怀疑是AI,尽管这是人类实力的体现。这种“优秀反而被疑”的荒诞逻辑,与Claude给人类打分的行为形成了镜像:AI在严格评估人类,人类则在拼命证明自己不是AI。当评分权被交到AI手中,人类是否已经站在了一个新的十字路口——我们既怕被AI取代,又怕自己不够配得上AI的“同事”?