大厂AI激战高考志愿:千问、元宝、百度、豆包,谁在为考生指路?

作文赛场初试锋芒:通义千问与GPT-4o并列冠军,文心一言垫底
在刚刚结束的2025年高考作文实测中,六大中外AI模型共同挑战全国一卷作文题。测评结果显示,阿里通义千问与GPT-4o凭借对材料主题的精准把握、与时代背景的高度契合,双双获得58分的高分,并列第一。DeepSeek以57分紧随其后,Kimi和豆包分别获得54分和53分,而百度文心一言仅得50分,排名垫底。评委特别指出,通义千问的文章“扣题最准”,其“真正的歌唱从不是声线的炫技,而是生命与时代的共振”等表述获得高度评价;而文心一言引用周杰伦音乐经历的做法被认为“匹配度不足”,豆包的标题也被指格局偏小。这一轮比拼为后续的志愿填报服务埋下了能力的伏笔——能写好作文的AI,是否也能填好志愿?
高考期间AI紧急“封口”:拍照答题功能全面禁用,各家应对不一
随着“高考期间AI工具将禁用”的话题在网络发酵,各大AI平台纷纷启动应急限制。豆包客服明确表示,高考期间拍题答疑等类似功能会被禁用;腾讯元宝方面表示,去年高考就已明确不答题;百度相关业务负责人则称暂未收到限制服务通知。回顾去年的举措,阿里通义App关闭了高考考试时段的拍照讲题服务;夸克App同样关闭答题服务;豆包App输入考试题目会显示“图片内容不合规,上传失败”;Kimi也显示“为确保高考的公平性,此功能在高考时段无法使用”。科大讯飞工作人员则指出,只要是大模型,高考期间应该都会有限制。这一系列“封口”措施,既体现了对考试公平性的维护,也折射出AI在特定场景下的“红线”。
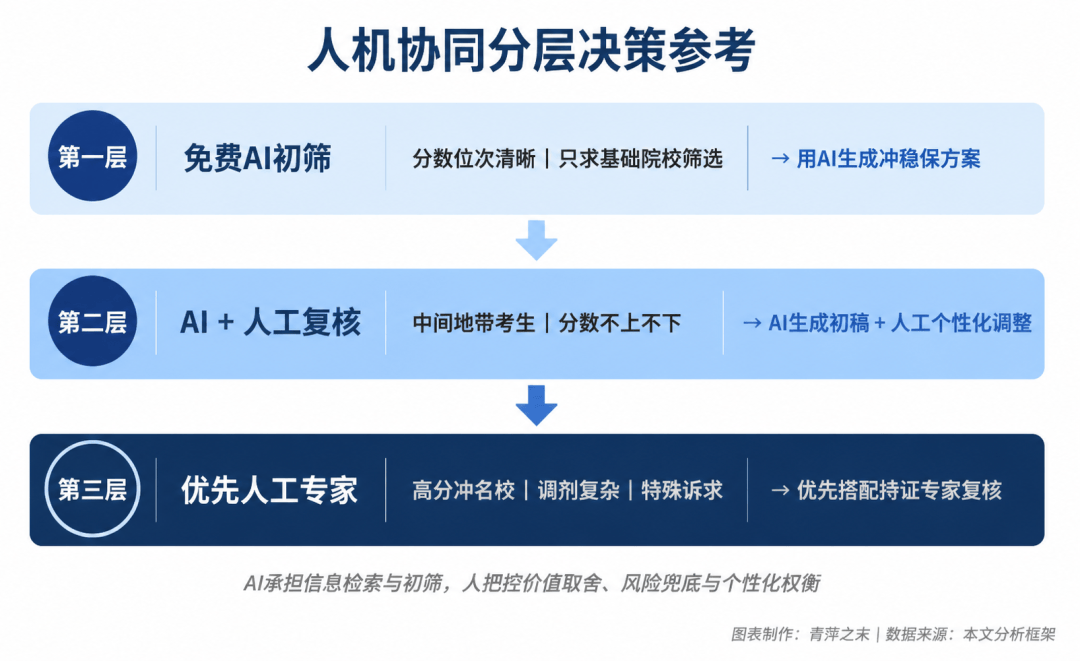
志愿填报实测:千问、元宝、百度、豆包谁更懂考生?
虽然高考作文表现各有千秋,但在志愿填报这一全新战场,AI的表现更受考生和家长关注。以一位江苏考生(选科历地政,总分627分)为例进行模拟填报,各平台给出的方案差异明显。阿里通义千问延续了其在作文中的“稳健”风格,推荐院校梯度合理,对专业选择的解读也紧扣“兴趣+就业”双线;腾讯元宝则更注重交互体验,通过深度思考链展示推导过程,让考生看到推荐背后的逻辑;百度文心一言在院校数据覆盖上较为全面,但存在部分专业描述过于笼统的问题;字节豆包在院校库更新及时性上表现突出,能够快速匹配最新招生政策。从模拟结果看,千问和元宝在综合推荐质量上略胜一筹,但豆包在响应速度和直观性上也有亮点。
模型“内心戏”上演:元宝的思考链展示让部分考生出戏
在本次测试中,所有AI均开启了深度思考模式并使用最新模型。其中,腾讯元宝的“思考链”展示成为一大特色——它会像人类一样逐步推理:“该生选科历地政,627分,排名省内前X%……优先考虑北京院校……根据往年录取数据,某大学法学专业有冲刺可能……”这种透明的推导过程虽然增强了可信度,但也有考生反馈“感觉像在跟一个絮叨的顾问聊天,容易让人出戏”。相比之下,通义千问和豆包则更倾向于直接给出结论和备选方案,省去了中间推演。这一差异反映出不同AI产品对用户场景的理解——在志愿填报这种高度紧张的决策中,有的考生需要详细逻辑来建立信任,有的则只想要明确答案。