DeepSeek服务出现重大中断,约12小时仍未完成修复

据三言科技等多家媒体报道,国内AI模型平台DeepSeek于3月29日晚间发生大规模服务中断,大量用户反映无法正常访问。此次故障从当晚22点左右开始,直至30日早上7点,持续时间超过12小时,目前服务已逐步恢复中。
事件背景与时间线
本次大规模故障始于北京时间3月29日晚上22点。从那时起,DeepSeek的网页端与移动应用程序出现了严重的访问异常。故障初期,大量用户在尝试访问服务时遭遇页面卡顿,功能加载失败。随着时间推移,问题并未在短时间内得到解决,故障状态一直持续到3月30日早上7时,共计约9至12小时。
用户受波及情况及具体表现
受此次中断影响,DeepSeek的用户体验受到严重冲击,主要表现在以下几个方面:
- 登录与基础功能受阻:大量用户反馈网页端和App频繁弹出“服务器繁忙”的提示,页面持续转圈或完全无法登录。
- 高阶功能限流:部分高阶功能受到严格限制。据用户实测,在故障期间,“深度思考”模式极度受限,4小时内仅能使用1次。
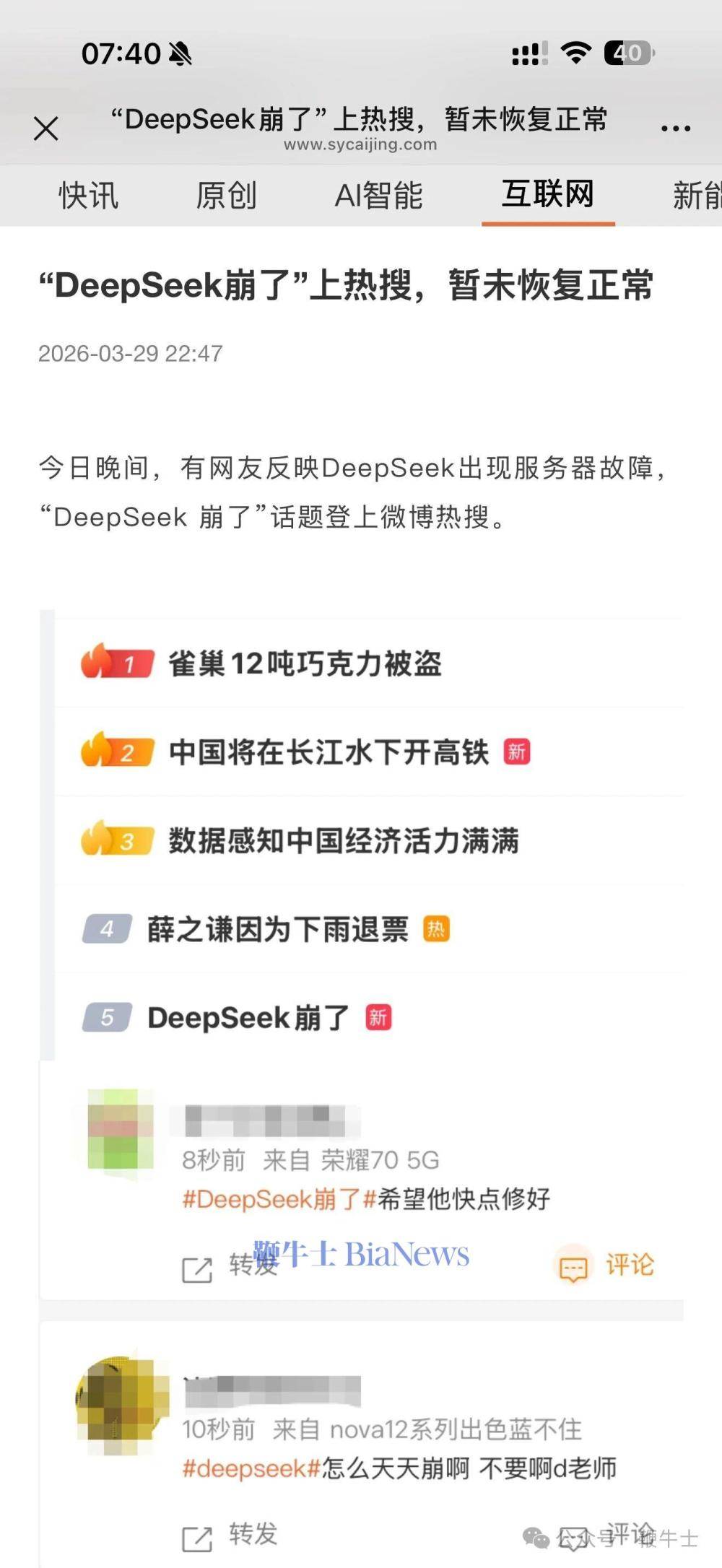
- 热搜话题发酵:由于故障波及范围广,大量用户涌入社交平台吐槽,导致“DeepSeek 崩了”这一话题迅速登上微博热搜,引发全网热议。
故障原因分析与上游服务
虽然截至发稿时DeepSeek官方尚未发布正式的故障声明,但从现有线索来看,本次事故很可能非DeepSeek自身应用层问题,而是源于基础设施层面。
- 上游供应商问题:类似OpenAI曾因上游提供商(Upstream Provider)导致故障,微软Azure也曾报告数据中心问题。本次DeepSeek的故障表现和持续时间,与底层云服务提供商的故障特征高度吻合。
- AWS云服务关联:参考资料中提到亚马逊AWS曾发布更新表示“正处理任务积压”,并指出问题源于其基础云服务提供商。考虑到DeepSeek等国内AI大模型通常依托于公有云基础设施,不排除本次故障与底层云服务商(如AWS或其他云基础设施)的波动有关。
后续修复与官方回应
截至3月30日早上,随着时间的推移,DeepSeek的服务已出现好转迹象。
- 服务恢复中:虽然故障持续了约12小时,但官方在随后的更新中表示正在处理积压任务。
- 官方声明缺失:截至目前,DeepSeek尚未就本次重大中断发布具体的事故报告或致歉声明,故障的具体技术细节及最终修复情况仍需等待官方进一步披露。