谷歌开源26B文本扩散MoE,劈柴:生成速度像赛马一样快

DiffusionGemma:一次性生成256个token的“赛马”级速度
谷歌CEO皮查伊在社交平台上形容DiffusionGemma“速度像赛马一样快”。这款模型不再像传统语言模型那样逐token顺序生成,而是引入扩散式输出头,一次性并行生成整块256个token的文本。每次前向计算都能让每个token“看到”其他所有token,从而大幅压缩解码时间。在单张NVIDIA H100上,token输出速度达到每秒1000+;在RTX 5090上也能跑到每秒700+。相比同等规模的自回归模型,推理速度最高可提升至4倍。
计算瓶颈转向:本地推理延迟痛点被破解
传统自回归模型在云端高并发场景中效率很高——服务器可以批处理成千上万用户请求,让硬件吃满。但在本地单用户环境中,逐词生成导致GPU大部分时间处于低利用率状态,大部分时间在等下一个token。DiffusionGemma通过一次性起草256-token块,让处理器每次拿到更大块的计算任务,把解码瓶颈从内存带宽转向计算本身。这意味着它的吞吐优势主要出现在低到中等batch size的单加速器场景,特别适合强调本地交互体验的开发者——行内编辑、快速迭代、生成非线性文本结构。
双向注意力与并行生成:在数独、代码补全等任务上大显身手
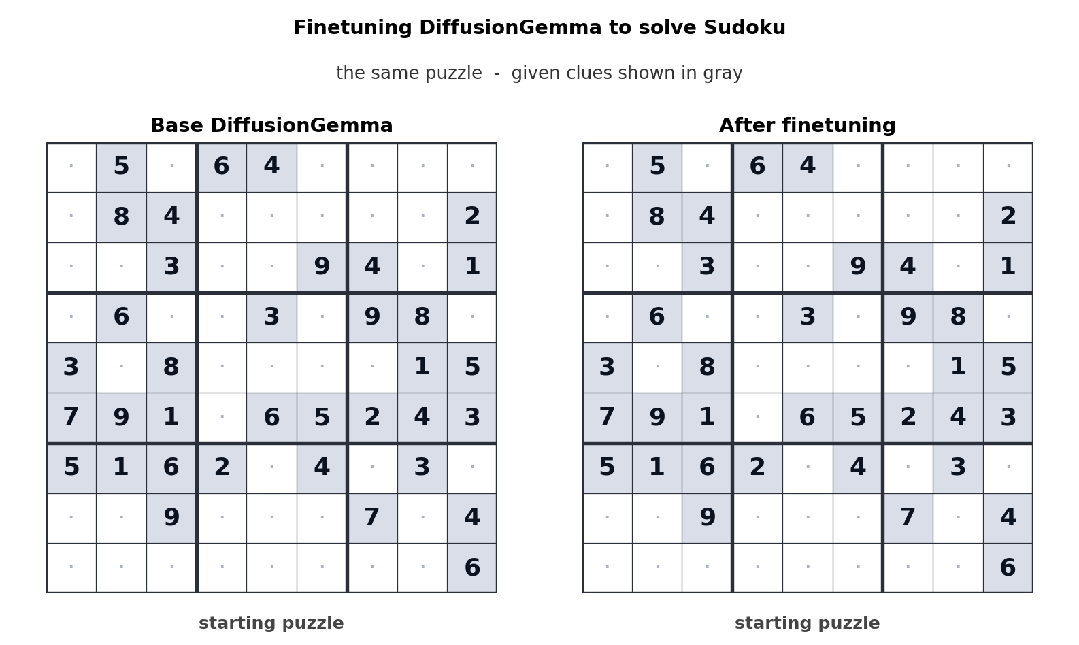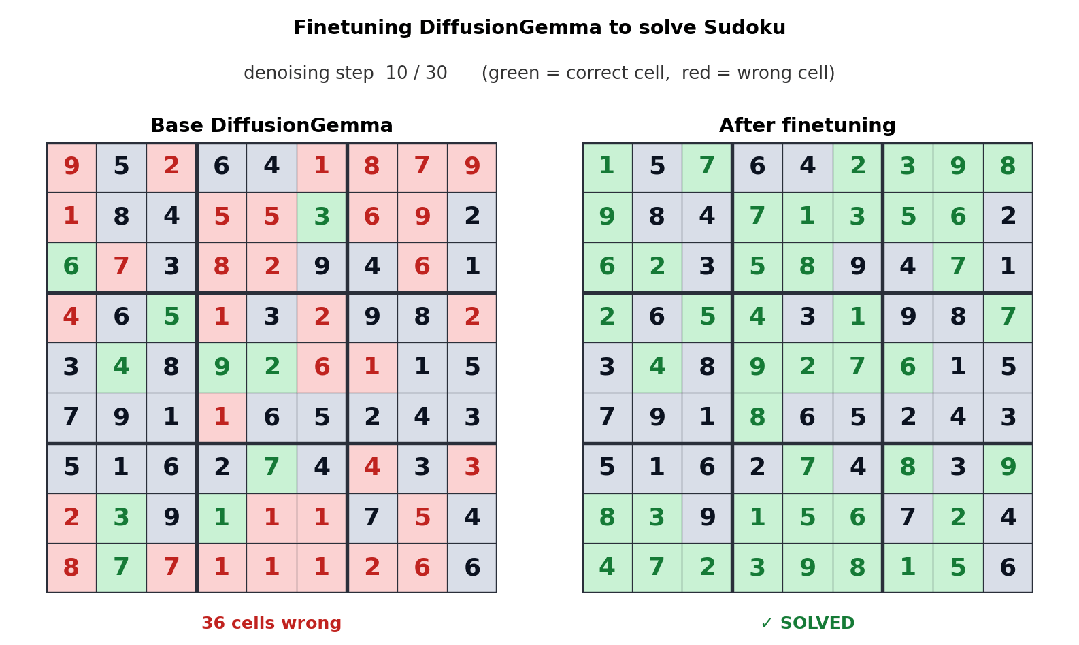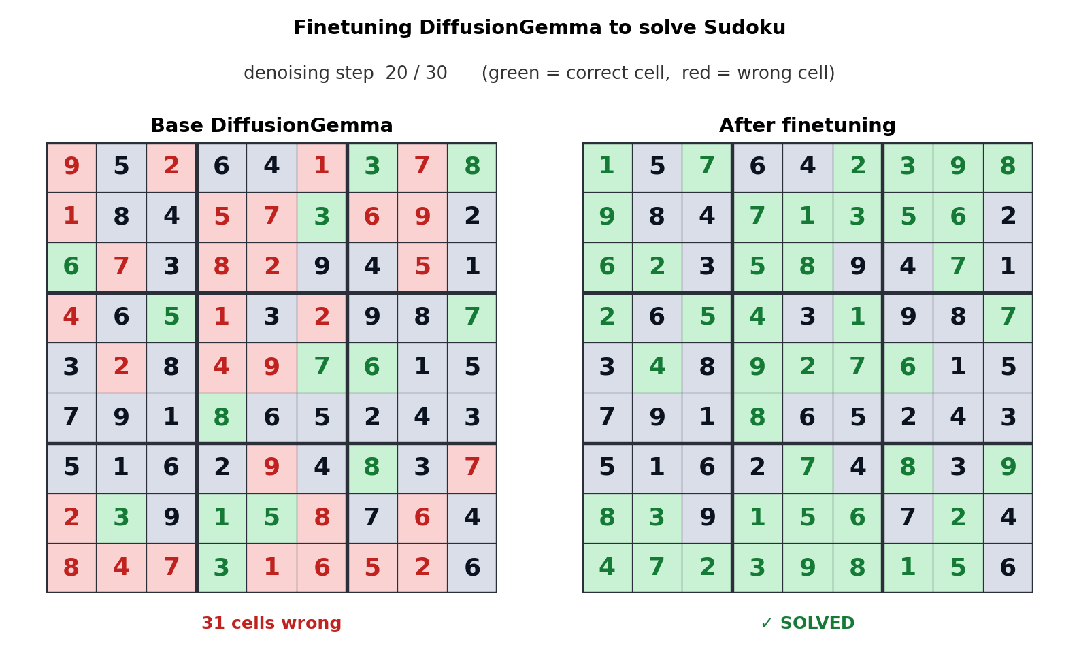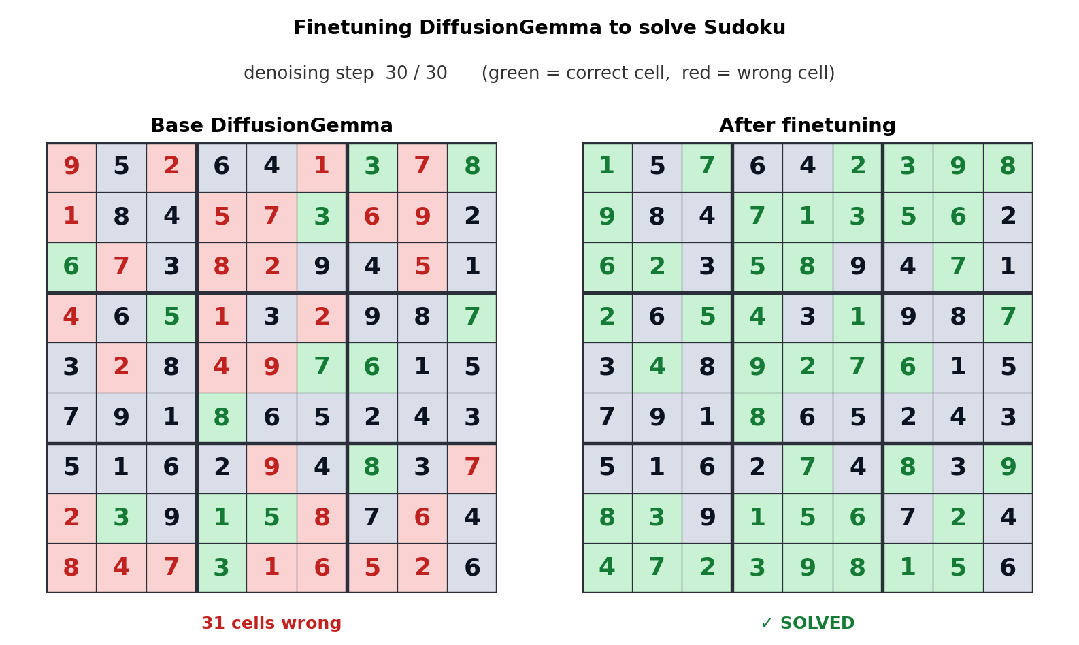
由于采用双向注意力机制,DiffusionGemma在非线性文本布局任务中表现突出。例如Unsloth团队针对数独任务对模型进行微调后发现:数独中每个token往往依赖后面的其他位置,自回归模型处理起来很吃力,而DiffusionGemma的并行全局视角让此类任务变得更容易。同样,在代码补全、氨基酸序列生成、数学图结构等场景中,模型可以通过多轮迭代不断refine输出,实时发现并修正错误。
实验性模型的取舍:速度虽快,质量仍需权衡
DiffusionGemma是一个26B规模的混合专家模型(MoE),但推理时只激活3.8B参数;经过量化后可在18GB显存以内的消费级显卡上运行。目前采用Apache 2.0许可证开源,建立在Gemma 4“每参数智能水平”之上。不过谷歌明确强调这是一款实验性模型——输出质量低于标准版Gemma 4。如果应用场景对文本质量要求最高,官方仍建议部署标准版Gemma 4;而DiffusionGemma更适合研究人员和探索速度优先的开发者,用于实时交互式AI应用、本地快速迭代等场景。