谷歌Gemma 4深夜突降,31B爆杀20倍巨头,手机跑全血「龙虾」

谷歌DeepMind近期再次在AI大模型领域掀起波澜,悄然发布新一代开源模型Gemma 4,其中31B参数版本表现尤为亮眼,不仅性能碾压多个20倍参数量级的竞品模型,还实现了在移动设备端的高效部署,引发行业广泛关注。
一、背景:谷歌持续深耕轻量高效模型
谷歌近年来在AI模型领域采取“大而全+小而精”的双线策略:
- 一方面推进Gemini系列超大规模模型,挑战GPT-4等主流模型
- 另一方面通过Gemma系列,专注于中小型模型的优化和开源
- Gemma 4是该系列中首次实现200亿以上参数仍可在手机端运行的突破
这一战略体现出谷歌对AI模型本地化部署和普及化的高度重视,也符合当前模型轻量化、高效推理的趋势。
二、Gemma 4亮点:31B参数版本横空出世
此次发布的Gemma 4包含多个版本,其中31B参数模型最为引人注目:
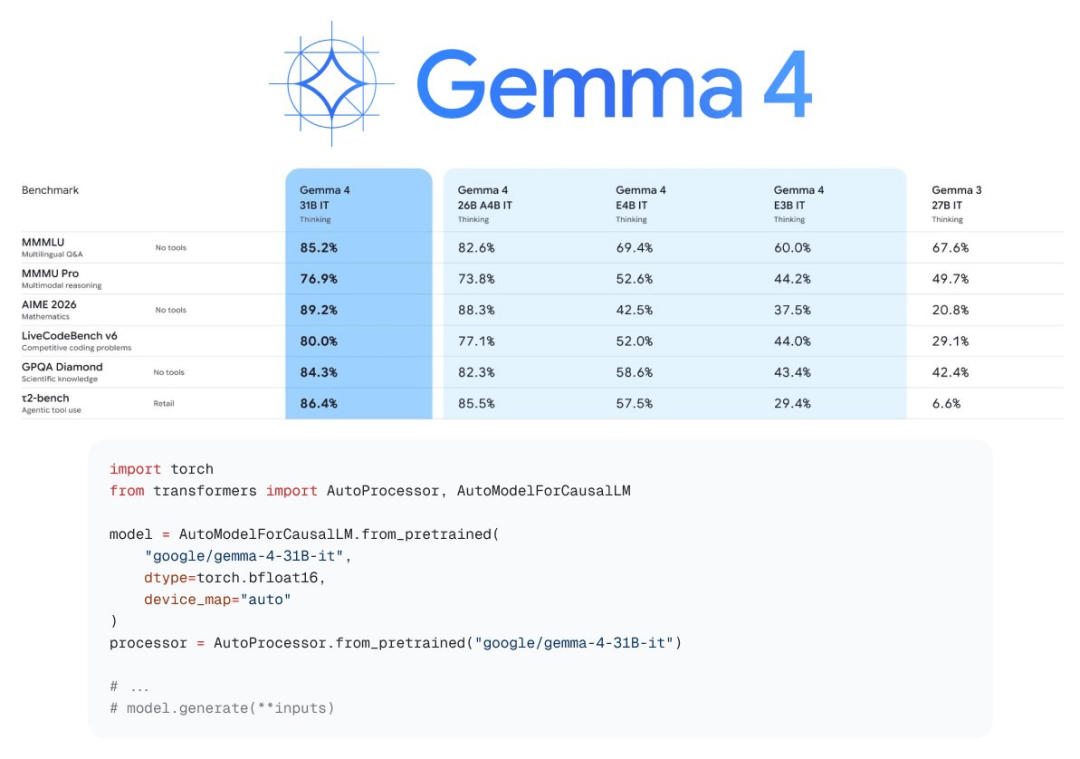
- 基于蒸馏技术优化,继承Gemma 2 27B的高效架构
- 在LongBench、Needle In A Haystack等长文本基准测试中表现优异
- 经压缩优化后,实测推理速度提升8倍,模型体积压缩6倍
- 一台3090显卡即可流畅运行,甚至支持iPhone部署
更令人震惊的是,Gemma 4的QAT(量化感知训练)版本已实现移动端全血运行,这意味着用户无需依赖云端服务器,即可在手机端完成复杂推理任务。
三、实测表现:手机端也能“跑全血”
谷歌团队在多个场景下对Gemma 4进行了实测:
- 在iPhone上运行2B版本时,性能已超越GPT-3.5
- Gemma 3 27B版本通过TurboQuant技术实现本地化加速
- 使用量化技术后,模型精度损失极小,推理速度大幅提升
- 手机端部署支持多语种处理、本地问答、智能生成等任务
这种“全血”能力意味着用户可以完全脱离网络,在本地完成从文本理解到生成的全套操作,极大地提升了模型的可用性和隐私保护能力。
四、技术影响:重塑AI本地化部署格局
Gemma 4的发布可能带来深远影响:
- 推动AI模型从云端向本地迁移,增强边缘计算能力
- 降低AI应用部署门槛,促进中小企业和开发者生态
- 可能改变行业对“大模型必须高性能硬件”的固有认知
- 加剧AI开源社区竞争,挑战Meta、OpenAI等厂商布局
此次31B版本的出现,再次证明了模型蒸馏和量化技术的潜力,为未来轻量化大模型打开了新思路。
五、未来展望:模型与设备协同进化
谷歌Nano Banana Pro AI等配套技术也在同步演进:
- 支持4K分辨率、多纵横比调整的AI生成能力
- 实现更精准的文本渲染与交互体验
- 可能与Gemma 4形成协同,进一步优化移动端表现
随着Gemma 4的推出,AI模型的“龙虾”时代或已来临——既能在高端服务器上“爆杀”大模型,也能在普通设备上“跑全血”,这标志着AI技术正从“少数人游戏”向“全民可用”转变。
如无意外,Gemma 4系列将很快被集成进更多谷歌产品中,并通过开源社区推动整个AI行业的本地化部署热潮。