Grok Imagine Video 1.5 模型正式上线:生成 6 秒 720P 视频仅需 25 秒

从图像到电影:25秒生成6秒720P视频
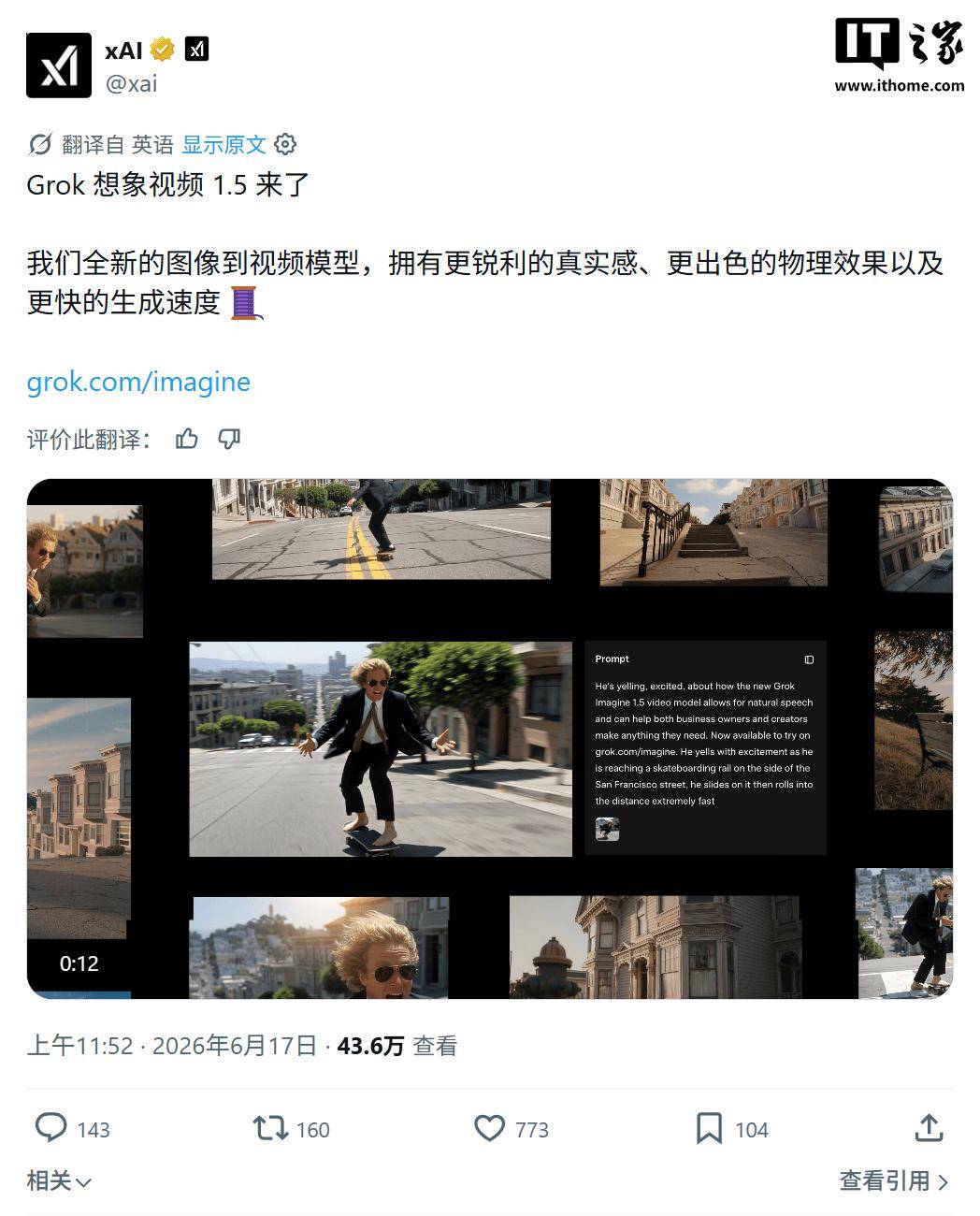
Grok Imagine Video 1.5的核心突破在于极致的速度与清晰度。只需上传一张静态图片——无论是产品照片、概念草图还是品牌素材——配合一段描述运动方向的文字提示,模型就能在25秒内输出一段6秒长的720P视频。相比多数生成模型需要数分钟甚至更久,这一速度大幅降低了视频制作的时间门槛。输出分辨率可选480P或720P,支持预览版快速迭代。
原生音频与视频续接:两把新钥匙
与上一代模型相比,1.5版本的两大新增功能尤为突出。其一是原生同步音频:生成的视频自动附带与画面匹配的音频,无需后期配音。其二是视频续接:可以对已有的视频片段继续生成后续画面,实现可控的叙事扩展。这两项能力让创作者从“素材拼接”升级为“一次性输出完整片段”,显著提升生产效率。
Aurora架构与11万块GPU:硬核算力底座
模型基于xAI自研的Aurora自回归混合专家架构,训练集群规模达到110,000块NVIDIA GB200 GPU。庞大的算力投入换来了更强的一致性、复杂多要素场景的Prompt遵循能力,以及更稳定的生成表现。与依赖扩散模型的竞争对手相比,这一架构在推理阶段的计算效率更高,也是25秒快速生成的底层技术保障。
登顶Arena排行榜:力压Seedance与Veo
Grok Imagine Video 1.5发布后立即登上Image-to-Video Arena排行榜首位,以52 Elo分的优势超越自家1.0版本,并击败了Seedance 2.0、HappyHorse 1.0与Google Veo。这一排名反映出模型在画质、动作合理性和音频同步三方面的综合胜出。同时,xAI在API中提供仅需几行代码的接入方式,直接与Seedance和Google Veo争夺开发者市场。
应用场景与开发者接入:一句话调用
对于专业创作者,该模型适合短策划、广告demo、概念验证和社交媒体短视频。以一张商品图生成动态展示片、一张概念图生成场景预演——这些场景只需一两句话就能完成。开发者可通过xAI API的Python接口快速集成,上传图像+描述运动+设定输出参数即可获得视频。对于生产团队来说,这可以替代部分真人实拍和后期特效,尤其适合快速迭代的创意思维。