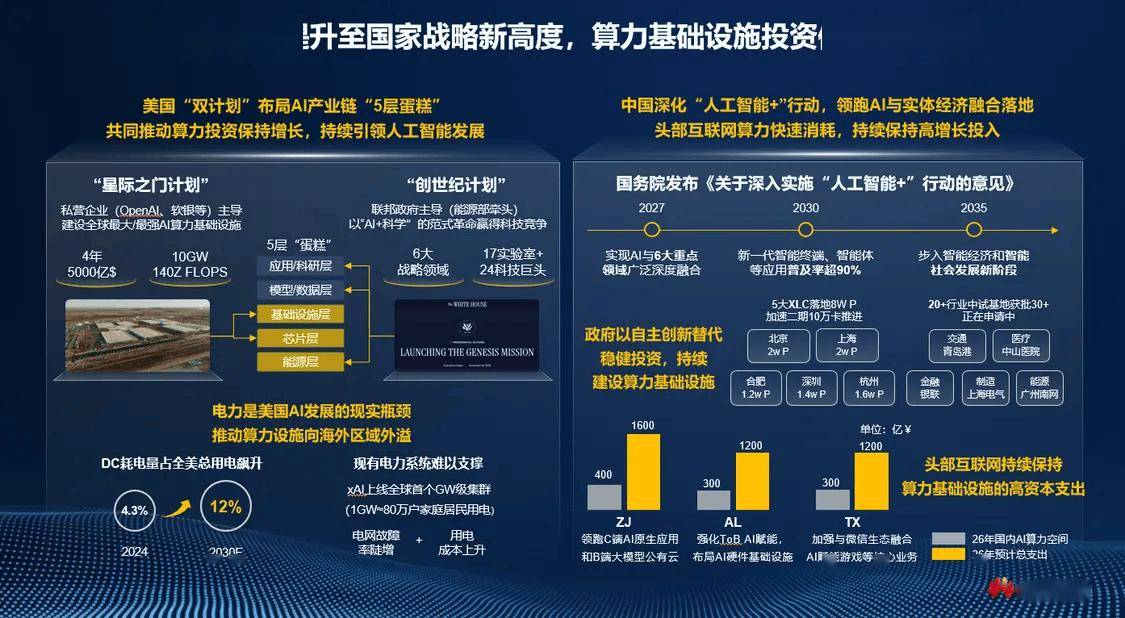
华为郑俊谈中美 AI 竞争:模型整体水平差距仅 2.7%,今年 2 月以来中国模型的调用量持续碾压美国

斯坦福报告揭示:中美模型差距已缩至2.7%
华为郑俊在近期公开分享中援引斯坦福大学的最新报告指出,中国AI模型整体水平仅落后美国2.7%,整体实力已无限接近国际先进水平。这一数据打破了外界对中国AI能力“代差”的刻板印象。郑俊强调,在模型性能快速趋同的背景下,中国AI产业正凭借强大的应用场景和数据规模优势,加速实现从“追赶”到“并跑”甚至“局部领先”的转变。
中国模型调用量“碾压”:OpenRouter平台前十大模型消耗占比超半数
郑俊特别提到,自2026年2月以来,中国模型的调用量持续碾压美国模型。这一趋势在第三方聚合平台OpenRouter上得到直观印证。数据显示,中国模型占该平台Token总消耗量的61%,前十大模型总消耗量达8.7万亿Token。其中,MiniMax M2.5以单周2.45万亿Token登顶榜首,Kimi K2.5和智谱GLM-5紧随其后。值得注意的是,编程应用成为消耗Token的最大类别,而智能体驱动的工作流程则贡献了平台输出Token总量的一半以上,反映出中国模型在复杂生产力场景中的实效优势。
算力成为薪酬“第四极”:工程师的年度Token预算或达薪资一半
随着模型调用量的爆发式增长,企业对算力资源的分配方式也在发生根本性变革。郑俊指出,部分企业已开始将AI推理算力视为工程薪酬的第四大组成部分——工资、奖金、股权之后,Token正在成为新的价值单位。未来每位工程师可能配备年度Token预算,其金额约为基础薪资的一半,以支持更高效的开发工作。这种“算力薪酬化”趋势,不仅推高了Token消耗,也使编程和智能体类应用成为算力需求增长的核心引擎。
从“模型竞争”到“应用生态”:中国AI的弯道超车逻辑
郑俊认为,中美AI竞争已从单纯比拼模型参数转向“模型+应用+算力”的综合生态较量。中国模型的调用量碾压,本质上是场景驱动、快速迭代的结果。从编程辅助到智能体点外卖,从图片生成到3D打印全流程闭环,中国企业在“人机协作”的落地层面展现出更强的适应性。与此同时,国内算力布局向政府基地和头部企业集中,推理服务与Token消耗深度绑定,形成了“模型能力提升→Token消耗暴涨→应用生态繁荣”的正循环。未来,智能体应用(如OpenClaw)将进一步把算力消耗推向新高度,而中国在这一赛道的先发优势正在加速扩大。