马斯克急推“美国编程版DeepSeek”,评论区:还不如免费的……

实测全场最佳:0.17美元规划,1.48美元交付一个微服务
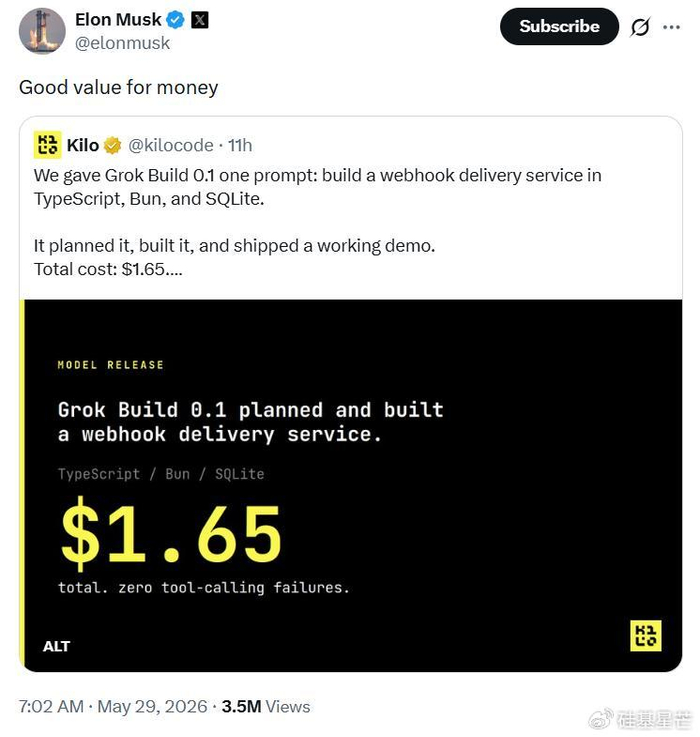
智能体平台Kilo Code发起了一场硬核实测,仅给Grok Build 0.1一个模糊指令——写一个包含退避重试、签名验证和数据库持久化的Webhook后端微服务。结果让人大跌眼镜:模型没有立刻输出代码,而是先联网调研Stripe和GitHub标准,然后向测试者抛出架构反问,生成一份包含ASCII架构图、Drizzle Schema定义和风险评估的规划报告,整个过程仅花费0.17美元。随后它一口气完成全部编码与测试,全程零工具调用失败,总成本1.48美元。这种“先规划、再动手”的Agentic工作流,让不少后端工程师感到职业危机。
定价凶猛:输入1美元/M,输出2美元/M,不到GPT-5.5的十分之一
xAI此次定价极具侵略性:输入1美元/1M tokens,输出2美元/1M tokens,仅为GPT-5.5和Claude Opus 4.8价格水平的十分之一。这被外界视为马斯克试图在硅谷复刻中国大模型路线的标志性动作——用极致价格重新定义AI编程性价比。然而评论区立刻有人泼冷水:“别被价格忽悠,免费的DeepSeek不香吗?人家上下文可是1M。”Grok Build 0.1仅有256K上下文窗口,在长上下文模型已普及1M的今天,这种容量在真实大型项目中根本无法装入足够历史上下文,导致幻觉频出、指令遵循能力差。
尴尬的“美国大豆包”:Grok正被阿里、Kimi、小米全面压制
在OpenAI、Anthropic、Google三家之外,阿里Qwen3.7 Max、月之暗面Kimi K2.6、小米MiMo-V2.5-Pro等国产模型已在多项基准测试中对Grok形成全面压制。尤其在Coding和Agentic领域,xAI已被甩出前十,在开发者圈子无人问津。Grok目前唯一的舞台是依托x平台的多模态能力和宽松内容限制,被网友戏称“美国大豆包”。Grok Build 0.1正是马斯克试图在编程这一垂直赛道自救的产物。
代码安全隐患:时序攻击、硬编码凭证、集成测试缺失
资深工程师深扒Grok几美元生成的源码后发现,问题不少:
- Webhook签名比对使用了普通字符串检查,而非抗时序攻击的
crypto.timingSafeEqual,对黑客来说如同敞开大门。 - 代码中留下了测试用的硬编码密钥和临时端点,在真实生产环境可能造成数据泄露。
- 编写了14个基础单元测试,但对自动暂停、重试循环等复杂业务逻辑的集成测试完全没有覆盖。
Kilo Code技术报告评论区有人直言:“AI不会消灭程序员,只会把程序员逼成更严苛的技术审查员。用Grok节省的几美元,迟早要花成千上万倍在安全补丁和系统重构上。”
拒绝跑分晒单营销:没有第三方基准,幸存者偏差疑云不散
马斯克这次发布依然延续“拒绝跑分、纯靠晒单”策略,但一年前的Grok Code Fast 1就曾因频繁翻车被诟病。虽然第三方评测机构公信力下降,但基准测试至少是“及格线”。缺乏第三方测试支撑,难免被质疑存在幸存者偏差式过度包装。xAI要想真正逆袭“御三家”,先得补齐超长上下文、遗留代码精准重构以及代码安全底线这几个硬伤。