中国第一、全球第二!HiDream-O1-Image-1.5 登顶文生图榜单,超越谷歌、英伟达

匿名盲测登顶,开源模型全球第一
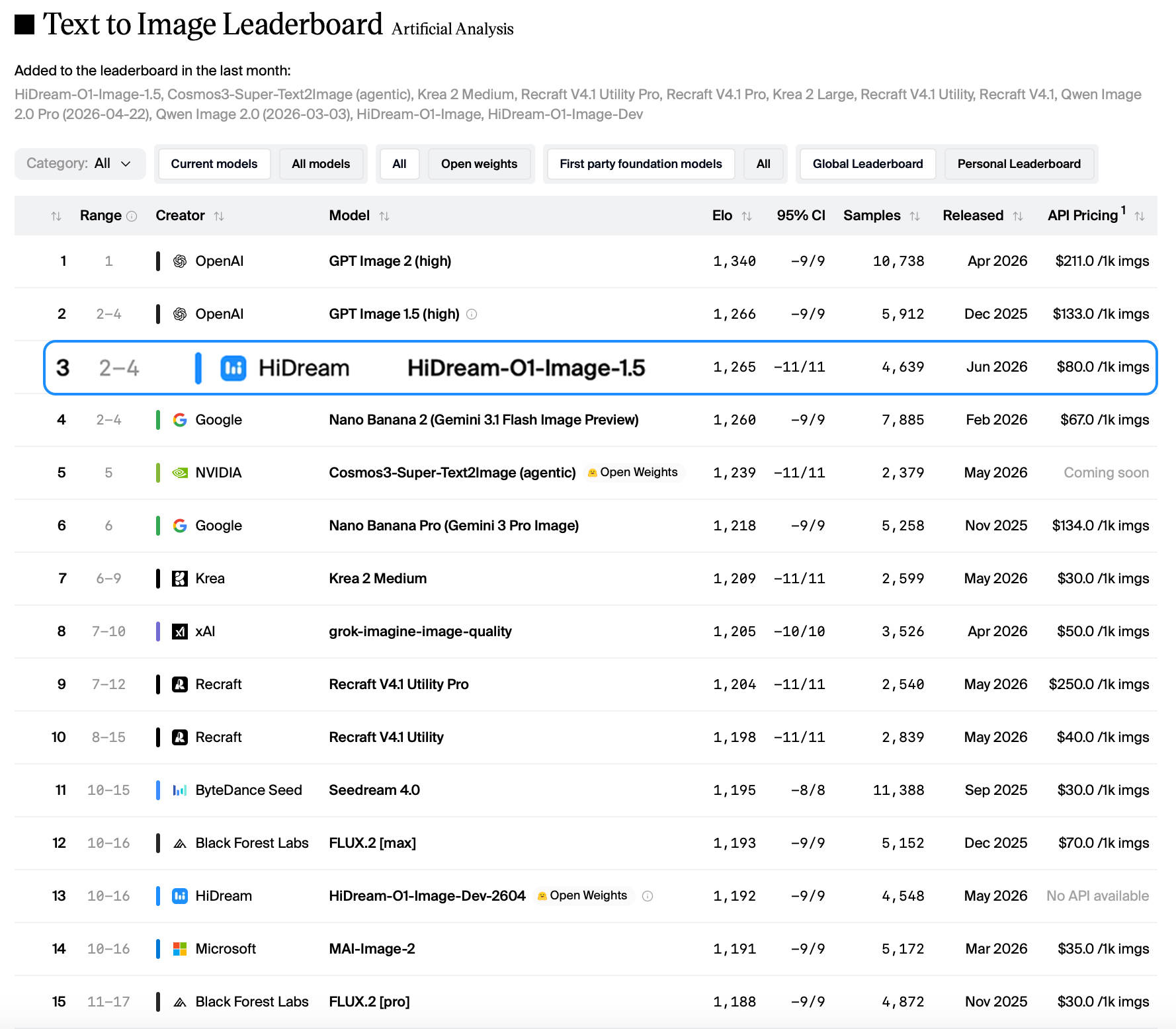
在Artificial Analysis Text to Image Leaderboard的Blind Arena盲测中,HiDream-O1-Image以隐藏身份出场,基于超过3000个样本的用户投票,拿下1187 ELO分数,登顶开源模型全球第一。该榜单依赖真实用户对匿名生成图像的偏好判断,而非固定题库打分,因此结果更接近开放场景下的真实体验。HiDream-O1-Image凭借8B参数规模,一举超越Z-Image Turbo、Qwen-Image(27B)、FLUX.2[dev]等更大参数的闭源与开源模型,成为全新架构挑战者。开源当日即冲上Hugging Face模型趋势榜前三,并持续上升。
两项核心创新:UiT架构与推理智能体
HiDream-O1-Image的性能背后是两项关键架构突破。第一,率先在开源领域跑通像素级统一Transformer(UiT)架构。与主流模型依赖VAE压缩和独立文本编码器不同,UiT将原始图像像素、文本Token及控制条件直接映射至共享Token空间,彻底消除模态转换损耗,从底层提升了高频细节保留与图文语义对齐能力。第二,引入“先推理、后生成”的O1机制。模型内置基于Gemma 4的推理智能体,在生成前自动启动思维链(CoT)推理,深度解析用户指令中的空间布局、物理逻辑与主体属性,将模糊意图重写为结构化控制指令。这使得模型具备“慢思考”能力,大幅降低专业级图像生成门槛。
长文本与多主体:商业场景的实力验证
在CVTG-2K、LongText-Bench等评测中,HiDream-O1-Image展现出强大的长文本生成能力,中文场景得分0.978,超越GPT Image 2的0.961。由于不依赖VAE压缩,字符结构还原更稳定,可清晰处理商品标签、促销文案、杂志标题等复杂排版任务。在UniSubject测试中,模型在4-11个主体的多参考组合场景中保持稳定,能准确保留人物、服饰、道具等各自外观特征,避免属性错位与元素丢失。这意味着模型能够直接用于电商运营、时尚穿搭、广告创意等需要“多商品、多人物同框”的真实商业生产流程。
不止于单图:多分镜与影视创作延伸
HiDream-O1-Image不仅擅长单图生成,还能在一次推理中生成多宫格连贯故事板,并支持人物远景、中景、近景、动作切换等镜头语言控制。模型保持同一主体在不同画格间的身份、服装与场景逻辑一致,可服务于短片创意、广告脚本、漫画分镜和视频首帧生成等影视前期创作。这一能力表明,它已从“图片生成工具”向“视觉生成工具”延展,具备进入专业影视工作流的潜力。基于UiT架构,智象未来超千亿参数图像模型即将面世,无限时长视频生成应用也即将上线。