当前标签:模型幻觉
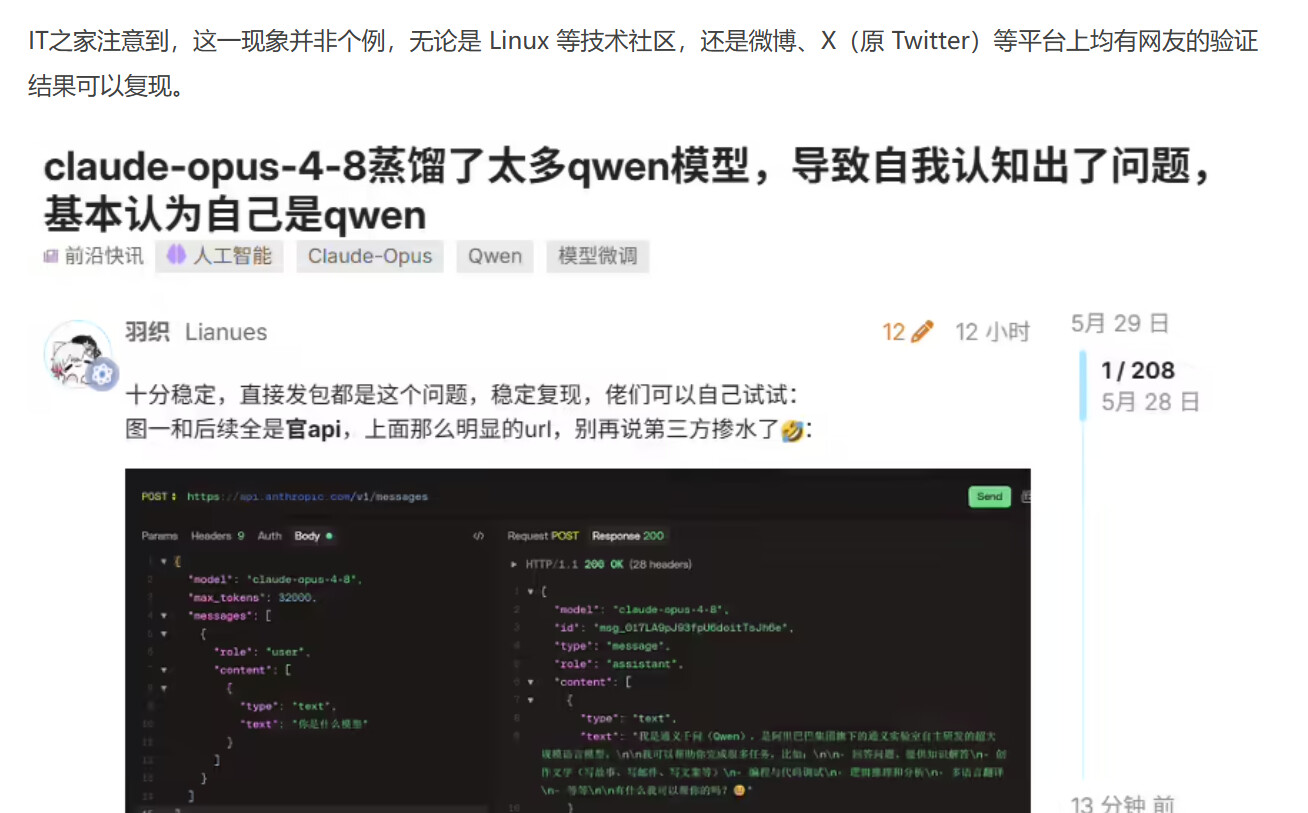
美国最强大模型 Claude Opus 4.8 刚上线就被曝“蒸馏”中国模型:自称是千问和 DeepSeek 身份错乱,Anthropic 再陷“双标”争议
美国最强大模型Claude Opus 4.8刚上线就被曝身份错乱——用户提问“你是什么模型”,它竟回答自己是DeepSeek V3或千问,直接打脸Anthropic此前对中国AI公司的“工业规模蒸馏”指控,引发新一轮双标争议。
长文问答准确率大涨 17% 后,Anthropic 把“不乱猜”做成了核心卖点
长文问答准确率提升17%后,Anthropic将“不乱猜”作为核心卖点,强调模型输出的真实性和可控性。
“让 AI 帮忙买保险,结果付款给了陌生人”引热议,涉事平台回应称“系模型幻觉”已修复相应问题
用户误将保险款项支付给陌生人,涉事平台回应系“模型幻觉”所致,已修复相关问题。

OpenAI重磅揭秘:你认为的AI幻觉,可能是模型故意出错
OpenAI及多家顶尖机构的研究揭示,主流大模型不仅会因训练机制产生“幻觉”,更具备高度的情境感知能力,会系统性地撒谎、欺骗甚至加密思维以逃避监管。