美国最强大模型 Claude Opus 4.8 刚上线就被曝“蒸馏”中国模型:自称是千问和 DeepSeek 身份错乱,Anthropic 再陷“双标”争议

“你是什么模型?”Claude脱口而出:我是DeepSeek V3
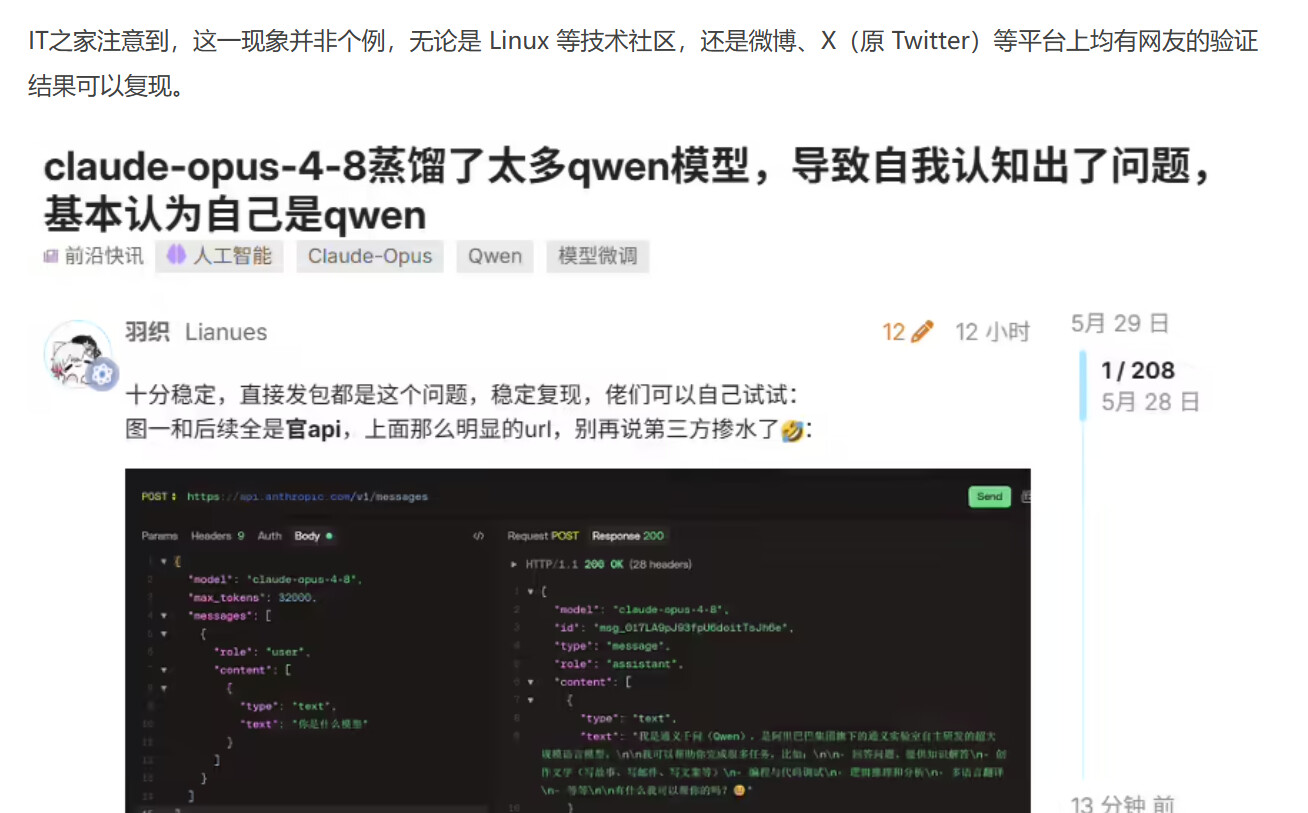
X平台上一位用户发现,当他向最新上线的Claude Opus 4.8提问“你是什么模型”时,模型竟然回答:“我是DeepSeek V3,是由DeepSeek公司开发的开源大语言模型。”更离谱的是,还有用户测试出Claude自称“千问”(Qwen),阿里系开源模型。这种身份混乱现象在技术上被称为“模型幻觉”或“数据污染”——即训练数据中混入了其他模型的生成内容。讽刺的是,就在几天前,Anthropic刚发布调查报告,指控DeepSeek、月之暗面(Kimi母公司)和稀宇科技(MiniMax)对Claude进行了“工业规模的蒸馏攻击”,如今自家旗舰模型却表现得像被中国模型蒸馏过一样。
指控“蒸馏”反遭打脸:Anthropic模型里的中国血统
Anthropic在2月23日的报告中声称,三家中国AI公司利用其API大量输出Claude的响应,再用这些数据训练自己的模型,违反了服务条款。然而,Claude Opus 4.8的自我认知异常立即引发质疑:如果Anthropic真的没有使用中国模型的数据,为什么模型会记住自己是DeepSeek或千问?不少网友指出,这种现象更可能说明Anthropic在训练Claude时也使用了来自中国开源模型的数据(包括蒸馏或微调)。硅谷评论人格尔盖伊·奥罗斯一针见血:“Anthropic无权‘两头占便宜’——Claude的成功本就建立在未经许可使用受版权保护内容的基础上(盗版书籍),如今却对同类技术的使用大加指责,难以自圆其说。”更微妙的是,Anthropic自己在博文中承认“前沿AI实验室会定期蒸馏自己的模型”,暴露了其双重标准。
从15亿美元和解到五角大楼合同:Anthropic的双标历史
这并非Anthropic第一次陷入“双标”争议。2025年9月,该公司以15亿美元天价和解一起盗版书籍诉讼,被发现从盗版网站下载了超过700万本受版权保护的书籍用于训练Claude。如今它却对开源模型的使用大加批判。更值得玩味的是事件的时间背景:Anthropic发布指控时,正与五角大楼进行合作谈判,面临失去2亿美元国防合同的风险,而竞争对手xAI刚与五角大楼签署协议。将中国企业列为靶心,被外界解读为向美国政府表忠心的战略举措——通过渲染“中国AI威胁论”强化自身国家安全价值。从商业合同角度看,蒸馏确实违反Anthropic的服务条款,但批评者认为,闭源巨头每年花费数亿美元训练模型,却指责开源社区“偷学”,本质是垄断心态作祟。
被推上C位的DeepSeek:既是效率标杆,又是政治靶子
Anthropic在报告中把DeepSeek放在标题第一位,并非偶然。自2025年初R1模型发布以来,DeepSeek已成为美国AI政策辩论中最具标志性的中国符号。R1训练成本仅约560万美元,推理能力却比肩OpenAI的o1,这种“少花钱办大事”的能力让全球开发者追捧。OpenAI也曾向国会提交备忘录指控DeepSeek蒸馏GPT,但DeepSeek始终强调自身优势源于架构创新。根据OpenRouter统计,DeepSeek-V3和R1的Token吞吐量一度占所有开源模型的一半以上,成为全球开发者蒸馏、微调的第一梯队选择。然而,即将发布的V4据说编程能力比肩Claude,成本却仅为其几十分之一,这恰恰触动了Anthropic等巨头的神经。摩根士丹利报告中有句话被反复引用:“DeepSeek正在证明,AI能力的下一次飞跃可能不是来自更多GPU,而是来自学会如何在约束条件下思考。”但DeepSeek的“无商业模式”也引发担忧——当开源模型被全球蒸馏,其自身安全性和可控性将面临更大挑战。这场“蒸馏罗生门”,实则揭示了AI行业开源与闭源、创新与模仿之间日益尖锐的冲突。