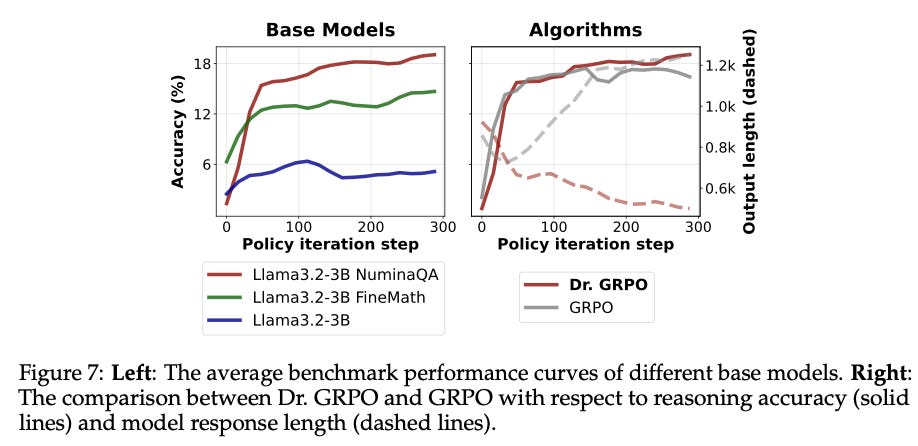
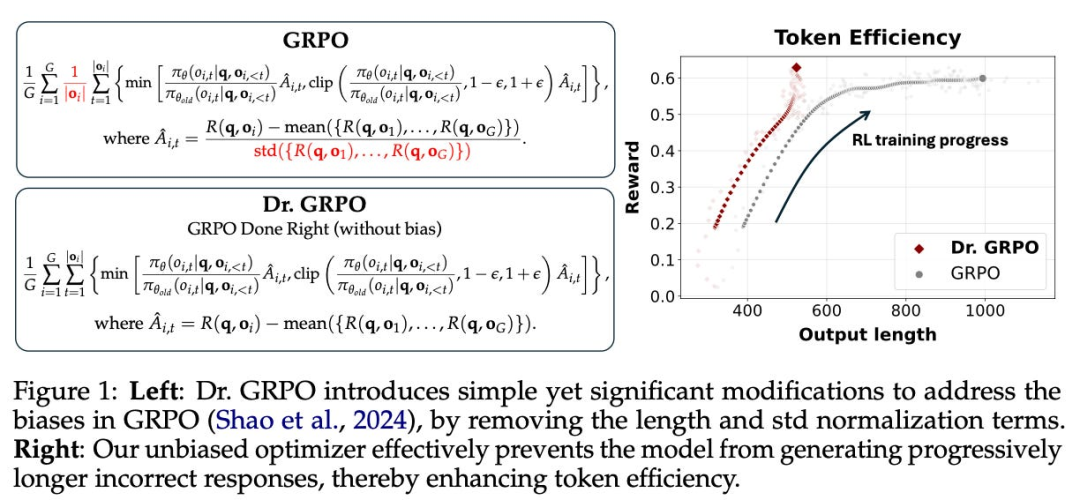
GRPO并未过时,反而通过理论突破(如2-GRPO将组规模降至2)和多种改进变体(DAPO、Dr. GRPO等),在降低计算成本的同时保持甚至提升了性能,成为推理模型训练的核心技术之一。
GRPO并未过时,反而通过2-GRPO等创新将训练时间缩短70%,并在DAPO、Dr.GRPO等改进中持续进化,成为更高效、更灵活的强化学习算法。