GRPO过时了吗?

2-GRPO揭秘:组规模从16降到2,训练时间缩短70%
传统观念认为,GRPO需要较大的组规模(如16)来保证训练稳定性,但这带来了巨大的计算开销。蒙特利尔大学、麦吉尔大学等机构的研究者在《IT TAKES TWO: YOUR GRPO IS SECRETLY DPO》论文中,从对比学习视角重新审视GRPO,揭示了其与直接偏好优化(DPO)的深层理论联系。他们提出极简变体2-GRPO,即组规模仅为2。通过严谨理论分析和充分实证,2-GRPO在性能上媲美传统16-GRPO,计算资源消耗大幅降低,训练时间缩短超过70%。这一发现为资源高效的LLM后训练RL算法开辟了新路径。
GRPO并非全新算法:它与PPO、REINFORCE同宗同源
很多人被RL在语言建模中的表现吸引,误以为GRPO开启了全新训练时代。实际上,GRPO与其他RL算法关系极为密切——它源自PPO(近端策略优化),并具有与RLOO(REINFORCE Leave One Out)超级相似的计算优势。REINFORCE与GRPO的唯一区别仅在于PPO的clipping逻辑机制,它们本质上都是同宗同源的策略梯度算法。前LLM时代流行的A2C算法,根据超参数设置不同,也可视为PPO的特殊变体。理解这一血脉关系,有助于避免对GRPO的盲目崇拜。
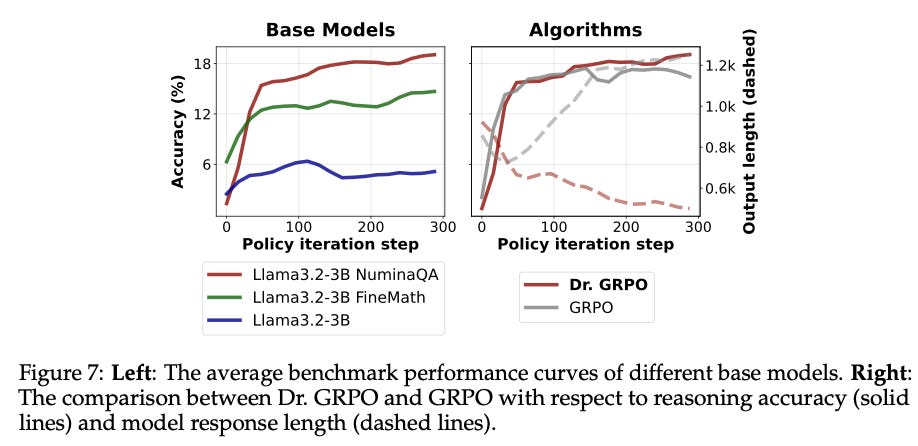
DAPO、Dr. GRPO、Kimi k1.5:GRPO的改进与实战
多个研究团队对GRPO进行了针对性改进。DAPO是首篇探讨改进GRPO以更好适应推理训练的论文,其将PPO/GRPO的裁剪超参数改为两个,使上限/正向对数比率步长可以更大,有利于增加推理链中新token的概率。Dr. GRPO则深入研究了从基础模型开始的强化学习,提出了简化改进方案。Kimi k1.5的训练实践报告了一个简单而有效的强化学习框架,无需蒙特卡洛树搜索、价值函数和过程奖励模型,仅使用正确性作为奖励,并移除了所有KL惩罚,允许模型自由变化响应长度,学习新行为。
GRPO的独特优势:负样本维持探索,非推理模型同样受益
GRPO因同时考虑负样本,策略熵下降较慢,能保持更长时间的探索能力,后期还能继续提升。负样本可能有助于维持探索,这是简单REINFORCE方法不具备的。此外,GRPO的改进效果不仅限于推理模型——对于Qwen-2.5和Llama-3这类非推理模型也表现非常出色。Predibase的实验表明,GRPO是适用于不同模型架构和能力的通用方法,可通过可编程奖励函数直接优化模型行为,无需人工标注偏好数据。
可验证奖励下的对比损失本质:GRPO与DPO的理论桥梁
在可验证奖励(RLVR)设定下,奖励是二元的(正确为1,错误为0)。论文推导证明了GRPO目标等价于一个对比损失:它推动模型增加正确回复的对数概率,同时减少错误回复的对数概率。当组规模趋于无穷大时,GRPO梯度公式与DPO梯度公式在结构上高度相似,二者在理论上紧密相连。这一发现不仅解释了2-GRPO为何能工作,也为设计新的资源高效对齐算法提供了理论基础。