Gem4大模型在千元机上的本地运行实测显示,生成一次结果需要约5分钟,性能瓶颈明显,本地AI体验依然依赖高端硬件。
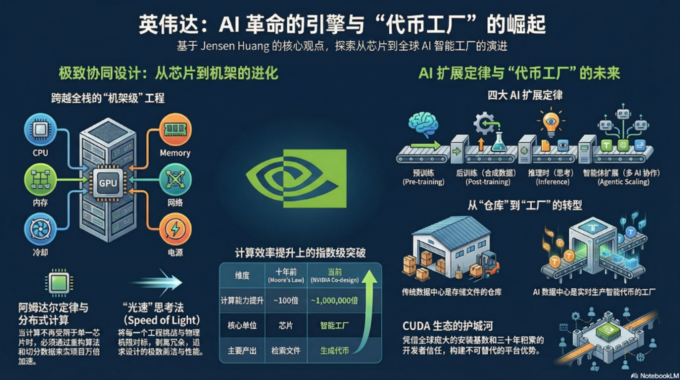
AI模型的Token效率正成为衡量“智力能效”的关键指标,驱动新一轮行业竞争格局的形成。