新架构模型HRM-Text创新纪录,1B参数、1000美元,图灵奖得主都亲自下场了

仅1B参数拿下三项高分,低成本训出高智商
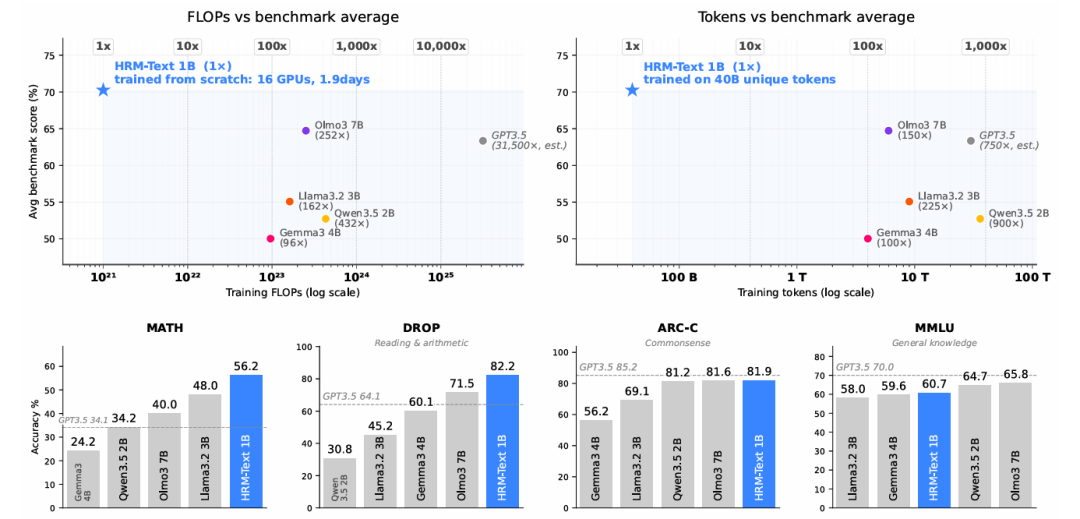
HRM-Text最令人惊讶的是其惊人的性价比。一个约1B参数的模型,在MATH上达到56.2分,在GSM8K上达到84.5分,在ARC-Challenge上达到81.9分,这些成绩在同等规模模型中堪称顶尖。更关键的是,训练成本仅约1500美元(另有消息称约1000美元),利用16块H100显卡跑了不到两天,便实现了此前需数倍预算才能达到的效果。
图灵奖得主亲自下场,背后是什么信号?
这款“千元模型”不止在学术界引发轰动,更吸引了图灵奖得主的直接参与。顶尖学者放下身段关注这样一个低成本模型,表明业界正对“大力出奇迹”的Scaling Law产生反思——当算力成本飙升,寻找更高效的架构和训练方式成为当务之急。HRM-Text恰好证明了:在资源极度受限的条件下,通过架构创新依然能逼近甚至超越大模型的推理能力。
“新架构”到底新在哪?并非简单堆算力
HRM-Text的成功并非靠暴力堆参数或延长训练时长,而是源于全新的模型架构设计。相比传统Transformer,HRM-Text引入了更轻量的注意力机制和特征复用手段,使得1B参数量就能释放出媲美3B-7B模型的逻辑推理潜力。这种“做减法”的思路,打破了“参数越大越强”的默认路径,为后续小参数、高效率模型的发展打开了新方向。
挑战OpenAI垄断:千美元级别模型的商业前景
此前,业界普遍认为高性能LLM的训练成本动辄百万美元,普通团队和个人难以企及。HRM-Text用不足2000美元的成本实现优异表现,意味着未来中小企业和研究机构有能力独立开发高质量模型,无需依赖巨头算力云服务。如果再配合量化、蒸馏等技术,甚至可以在消费级硬件运行千元模型的推理服务,对AI落地产生深远影响。