最小仅2B!谷歌最强开源模型登场,免费商用,手机就能跑

背景与定位
Gemma 4是谷歌DeepMind推出的全新开源模型系列,继承自Gemini技术体系,主打“智能密度”与部署灵活性。与Gemini不同的是,Gemma系列采用Apache 2.0许可证,允许开发者自由修改、再分发并用于商业用途。此次发布的模型包括E2B、E4B、26B MoE和31B Dense,覆盖从移动端到云端的全场景部署,标志着谷歌在开放AI模型生态方面迈出重要一步。
模型配置与性能表现
- E2B与E4B:专为边缘设备优化,支持在手机、树莓派、NVIDIA Jetson Orin Nano等设备上完全离线运行,延迟接近实时。
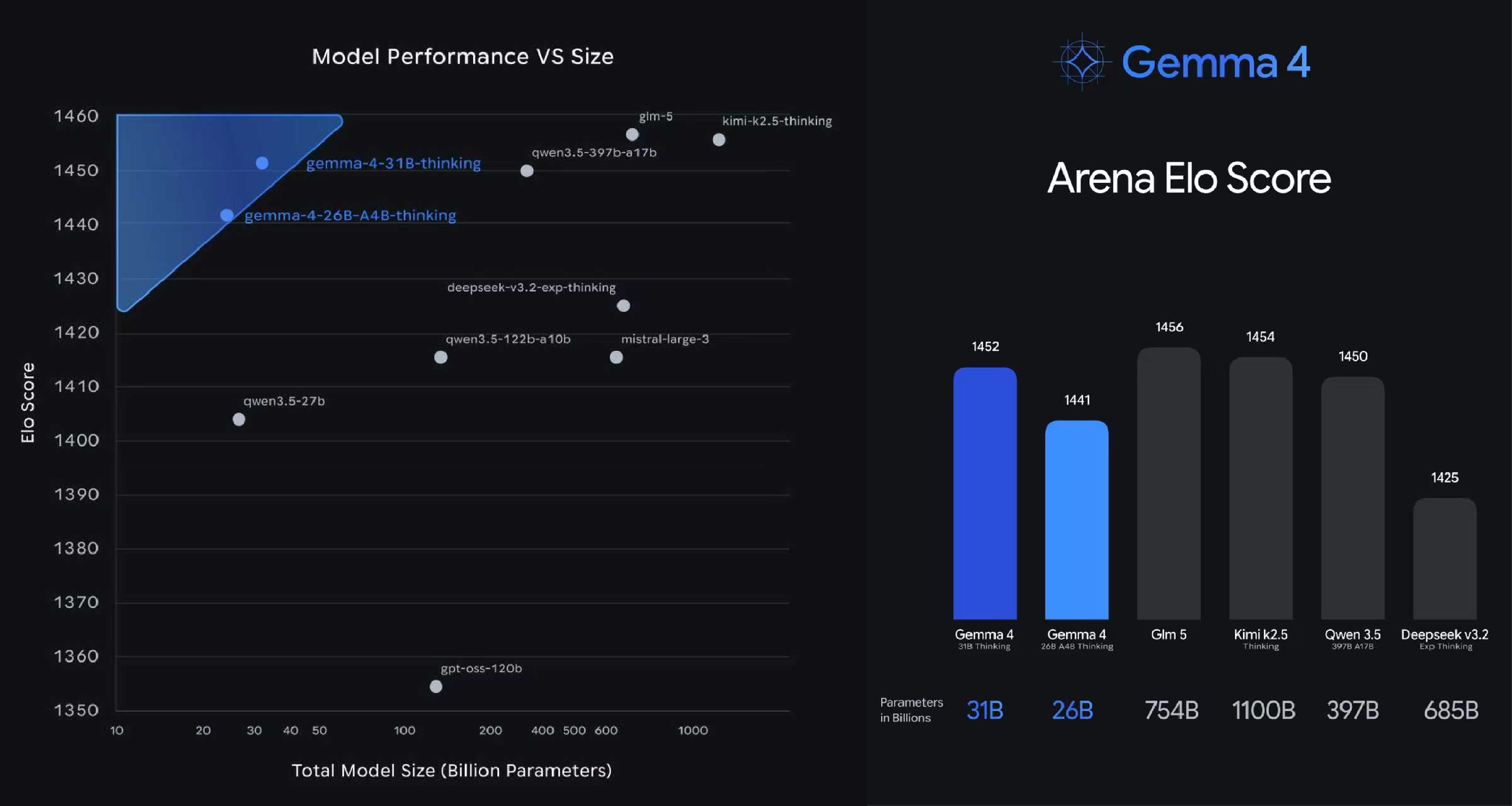
- 26B MoE:混合专家架构,推理时仅激活约3.8B参数,兼顾性能与效率,在Arena AI文本排行榜位列第6。
- 31B Dense:稠密模型,Arena AI文本排行榜位列第3,在高难度科学推理基准GPQA Diamond中准确率达85.7%,接近Qwen3.5 27B的85.8%。
该系列在多个关键指标上实现飞跃,如在AIME 2026数学推理基准中,Gemma 4 31B从20.8%跃升至89.2%;在代码生成能力方面,其Codeforces ELO评分从110分提升至2150分,达到接近专家级水平。
多模态与智能体能力整合
Gemma 4系列从架构层面支持图像、视频(帧序列)、音频和文本多模态输入,E2B与E4B还具备语音理解能力。其支持可变分辨率与多档token预算(70至1120 token),灵活适应不同应用场景:
- 低预算:用于图像分类、视频帧理解等高速度需求任务
- 高预算:处理OCR、文档解析、细粒度图像分析等复杂任务
此外,Gemma 4具备原生的函数调用能力,可直接输出结构化JSON,支持多工具调用与多轮任务执行,显著降低构建智能体系统的工程复杂度。
开源策略与部署生态
此次开源策略的转变尤为关键,Gemma 4系列采用Apache 2.0协议,取代此前的限制性授权方式。开发者可以:
- 免费商用部署,无需支付版税
- 自由修改与再分发模型
- 在本地设备或边缘硬件上运行,增强隐私保护与数据控制权
工具链方面,Gemma 4发布即支持主流框架如Hugging Face、vLLM、llama.cpp、Ollama、MLX等,模型权重可通过Hugging Face、Kaggle等平台下载。在硬件优化上,已适配NVIDIA GPU(从Jetson到Blackwell)、AMD GPU(ROCm生态)及谷歌自研TPU。
实测表现与参数效率
知名开发者Simon Willison在测试中指出,Gemma 4在“单位参数智能密度”方面表现出色。尽管最小版本(E2B)在处理多模态复杂任务时仍有局限,但中等规模模型(如31B Dense)已能胜任高难度推理与代码生成。
在GPQA Diamond测试中,Gemma 4 31B模型准确率达85.7%,接近Qwen3.5 27B的85.8%,远超人类专家平均65%的水平。这表明其在科学推理等高阶任务上具备真正的知识理解能力,而非依赖外部检索。
Gemma 4还通过结构优化提升小模型能力,如引入Per-Layer Embeddings(PLE)机制增强表达力,注意力机制采用局部滑动窗口与全局注意力交替使用,在最后一层使用全局注意力以兼顾长上下文与内存效率。
结语
Gemma 4系列的发布标志着开源模型从“可用”迈向“可部署”的新阶段。凭借其多模态能力、函数调用原生支持、跨平台部署与Apache 2.0许可,它为开发者提供了一个灵活、高效、可商用的模型工具。无论是在资源受限的移动设备上实现轻量化推理,还是在高端GPU上追求性能极限,Gemma 4都展现出极高的适应性与技术前瞻性,成为开源AI模型生态中的重要一员。