4步出声,单卡0.24秒!Noiz AI联合港科大清华,开源音频生成大模型

速度新标杆:RTF低至0.1,单卡生成仅需0.24秒
Noize AI在2026年实现合成速度的飞跃式提升。根据官方数据,其RTF(实时率)已降至0.1,为全网第一。这意味着用户只需输入脚本,模型即可在单张显卡上以0.24秒的超低延迟完成高质量音频生成。结合“4步出声”的极简流程——从选择音色、输入文本、调整参数到导出音频,整个过程不再需要等待,创作者可以像打字一样快速产出声音内容。
成本大降:万字符不到1元,人人用得起
价格门槛被彻底打破。Noize AI宣布万字符合成费用不到1元,相比此前动辄数十元的AI配音服务,成本降低了90%以上。这一策略直接面向40万短视频博主、漫剧创作者等高频用户群体,让高质量的AI配音不再是专业工作室的专属工具。同时,平台全面支持OpenClaw、扣子等API接入,方便开发者集成到自己的应用中,进一步降低使用成本。
克隆自如:10秒音频即可创建声音克隆
声音克隆变得前所未有的简单。用户只需提供10秒钟的清晰音频,就能快速创建与真人几乎无差别的模型;若提供几分钟的音频,效果会更加逼真。这一功能让创作者可以保留自己或特定角色的声音特征,并在所有项目中保持一致的语音识别,不再需要反复录音。基于新推出的两阶段训练流程,模型先利用水平拼接的单人数据学习多人说话模式,再通过多人数据精调,优化生成视频人物的真实感,甚至能处理多人对话场景。
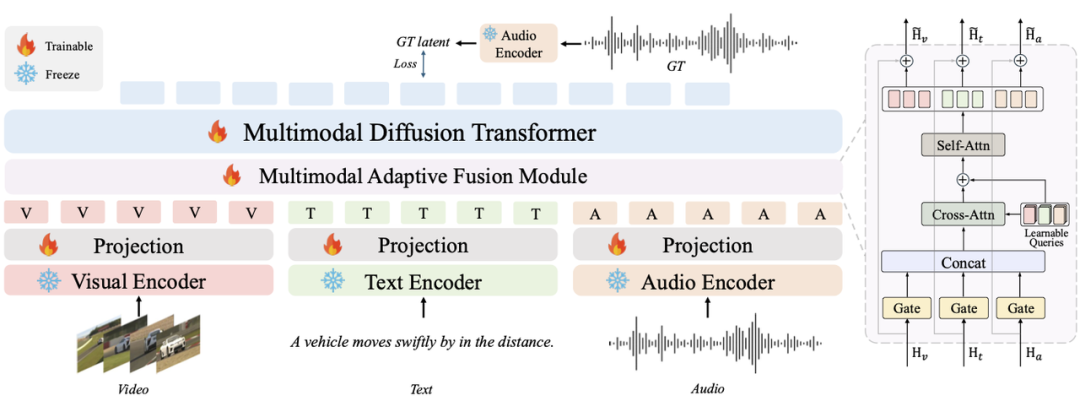
与高校联手,模型全面开源
Noize AI联合港科大、清华大学的研究团队,正式开源了音频生成大模型。开源版本不仅包含了完整的推理和训练代码,还提供了多个预训练音色模型。开发者可以在GitHub上自由下载、定制和再发布,无需担心商业授权问题。这一举措旨在推动AI音频技术的民主化——任何人都可以在自己的硬件上部署模型,无需依赖云端调用,实现离线或私有化部署。开源社区的热情反馈已经让模型成为音频生成领域的热门项目,预计将加速更多创新应用如语音助手、有声读物、游戏配音等的落地。