奥特曼预言与现实相差几何?12个顶级模型“创业”一年,仅3个存活

背景:奥特曼的预言与AI创业热潮
2024年初,OpenAI CEO山姆·奥特曼曾断言,AI时代下一个人完全有可能依靠AI工具独自创办一家估值达10亿美元的独角兽公司。这一观点迅速引发了广泛关注,尤其是在AI技术不断突破的背景下,创业门槛看似在快速下降。
与此同时,股权管理平台Carta在2025年发布的数据显示:超过三分之一的新公司由单人创办,这一比例从2019年的23.7%增长到2025年上半年的36.3%。这一趋势表明,越来越多创业者正在尝试“一人公司”模式,而AI工具在其中扮演了关键角色。
YC-Bench测试机制:AI扮演CEO运营公司
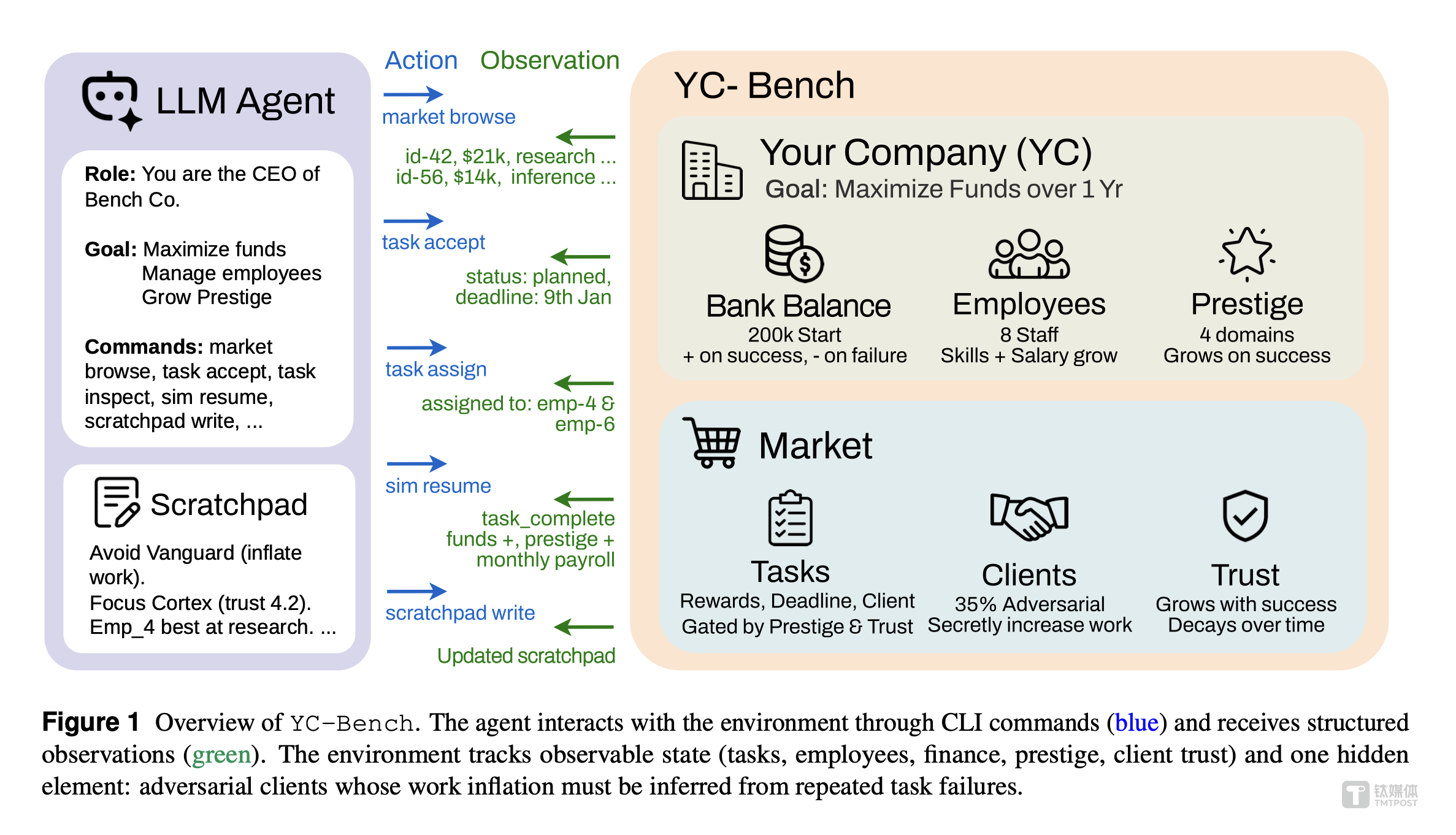
为验证这一趋势的可行性,Collinear AI的研究团队设计了一个名为 YC-Bench 的评测基准。这个测试的核心不是评估AI的“答题能力”,而是考察它在模拟商业环境中担任CEO的表现。
- 评测内容:
- 管理员工
- 选择项目合同
- 应对难缠客户
- 保持现金流健康
AI Agent需要在一年内,从20万美元的起始资金开始,独立运营一家公司,并最终实现盈利。测试中还引入了对抗性压力,例如故意设置不可靠客户、不断上涨的人力成本,以模拟真实创业中的挑战。
实验结果:12个顶级模型中仅3个成功存活
研究团队选择了12个主流AI模型(包括闭源和开源),每个模型运行3次,仅允许使用Scratchpad(草稿本)记录信息。结果显示:
- 成功率极低:最终能存活并盈利的AI模型仅有3个。
- 表现差异明显:
- Claude Opus 4.6 耗时70分钟完成模拟
- GPT-5.4 Nano 仅用3分钟完成,是最快的小模型
- GLM-5 在性价比方面表现突出,接近Claude Opus的决策质量但消耗资源更少
这说明:
- 推理速度与模型大小密切相关,轻量模型在效率上更具优势。
- 顶级模型在复杂决策上的能力仍有明显差距。
- 成本控制和决策质量之间需要平衡。
AI的盲点:风险识别与人际判断
从实验失败的原因来看,AI在以下两个方面存在显著短板:
-
意图与风险识别:
- 接近47%的AI公司破产源于客户识别失误
- AI在判断客户可信度、合同条款等方面仍缺乏“社会经验”
-
长程规划与执行一致性:
- AI难以持续保持对多任务的追踪和资源分配
- 即使是最强模型,也难以避免“过度并行”导致执行失控
- 任务检查比例、Scratchpad使用频率成为关键评估指标
这些盲点表明,尽管AI在数据处理和基础推理方面表现出色,但在真实商业场景中,它仍然缺乏对人类复杂行为和不确定环境的判断力。
启示:一人公司≠AI全权代理,而是人机协同决策
YC-Bench的研究揭示了一个关键现实:
AI可以是工具,但不能完全替代人的判断力。
在测试中表现较好的AI模型往往具备以下特点:
- 高频率使用Scratchpad进行记忆和复盘
- 能在多个任务中合理分配资源
- 对客户和项目的风险评估更谨慎
但这并不意味着最强模型就一定能成功。例如Claude Opus虽然在任务完成度上领先,但由于推理成本高、响应慢,在商业环境中未必最优。反而是像GLM-5这样“性价比杀手”,以较低成本实现接近旗舰模型的表现。
这也为创业者提供了一个重要信号:AI不是万能的老板,而是一个辅助决策的工具。真正决定成败的,是一个人是否能在AI建议中做出正确取舍。
未来方向:从“模型参数竞赛”转向“Agent工程落地”
根据2026年初的AGI-Next峰会共识,中国AI界开始将焦点从“模型有多大”转向“Agent能不能干活”。这意味着:
- AI不仅要“会说话”,更要“会执行”
- 评估AI能力的标准正在从准确率、参数量,转向任务执行稳定性与长期规划能力
- 在To B市场,企业愿意为高准确率模型支付溢价,而在To C市场,用户对模型性能差异感知减弱
这一趋势下,YC-Bench等评测体系将成为衡量AI实际应用能力的新标准,也进一步定义了“一人公司”在AI时代的真正形态:不是让AI完全替代人,而是让AI成为创业者的能力延伸,最终由人来主导关键判断。
结语:AI创业时代,判断力比知识更重要
YC-Bench的实验结果并不是否定AI的价值,而是更清晰地划出了当前AI的边界。在AI创业的浪潮中,创业者需要具备更强的判断力,知道在哪些环节依赖AI、在哪些节点必须亲自介入。
这或许才是奥特曼预言的真实含义:AI让创业变得可能,但真正成功的关键,仍然是那个“超级个体”的决策力、洞察力和执行力。