阿里开源首个统一科学大模型 LOGOS,仅用 1/56 参数超越微软 NatureLM

参数仅对手 1/56,性能却全面碾压
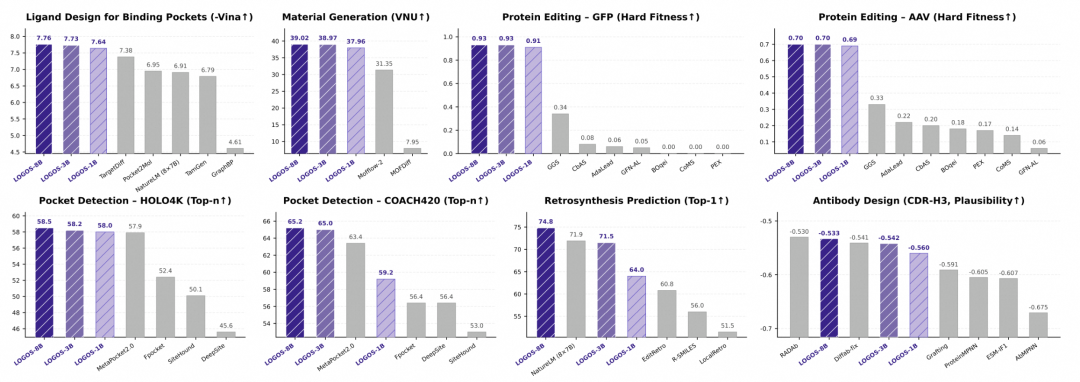
阿里云最新开源的统一科学大模型 LOGOS 在科学智能领域引发震动。该模型仅用相当于微软 NatureLM 1/56 的参数规模,却在小分子设计、蛋白质-配体结合、RNA 编辑等跨学科任务中实现全面超越。NatureLM 是微软研究院科学智能中心开发的序列基础模型,覆盖小分子、蛋白质、材料、DNA 和 RNA 等五大科学领域,被誉为“自然语言模型”。而 LOGOS 通过更精简的架构和阿里积累的高质量科学语料,在同等测试集上取得更优的生成质量与结合亲和力预测精度。这一成果表明,参数量的“军备竞赛”并非科学模型唯一路径,算法和数据质量的创新同样能实现弯道超车。
跨学科统一建模:从分子到基因的“语言破译”
与 NatureLM 类似,LOGOS 同样采用序列化建模方式,将小分子的 SMILES 字符串、蛋白质氨基酸序列、DNA/RNA 碱基序列以及材料晶体结构统一映射为“自然语言”,并通过大语言模型进行学习。但 LOGOS 的突破在于引入了阿里自研的多模态联合训练技术——模型不仅理解各个学科的“语法”,还能在跨领域任务中实现端到端推理。例如,当用户输入“设计一种能结合某蛋白受体的药物分子”时,LOGOS 可直接输出候选化合物 SMILES,而 NatureLM 需分步调用多个专用模块。这一统一框架大幅降低了跨学科研究的门槛,让生物学家、材料学家和化学家能用同一套工具对话。
开源全家桶:模型+训练框架+工具链一次性放出
阿里云此次开源 LOGOS 采用了业界罕见的“全家桶”策略。除了模型权重,还同步开源了专用训练框架 FlagScale(基于 Megatron-LM 扩展,支持分布式优化器和流水线并行)以及高效注意力算子 FlagAttention(包含分段式 PiecewiseAttention 算法,显著降低长序列推理显存占用)。这种开放性对比微软 NatureLM 仅开放论文和部分代码的做法,更有利于全球科研社区复现和改进。阿里云延续了通义千问“全尺寸、全模态”的开源路径,从 0.5B 到 480B 参数的科学模型版本全部开放,开发者可根据算力资源按需部署。据统计,通义千问系列衍生模型已超 18 万,全球下载量破 7 亿,此次 LOGOS 的开源预计将再次点燃科学智能领域的创新热潮。
推理能力与长文本处理:用自然语言驱动科学研究
在关键能力评测中,LOGOS 展现出惊人的推理与长上下文适应能力。在集成推理数据集 IRD 测试中,LOGOS 的归纳、演绎和因果推理准确率仅次于 GPT-4,全面超越 NatureLM 和 Llama 2-70B。其上下文窗口通过 NLPE 位置编码方法从 4K 扩展至 32K,可在单次推理中处理完整的蛋白质-配体交互文献或基因编辑序列,将科研人员从繁琐的“读论文-写代码-跑实验”循环中解放出来。例如,在针对 CRISPR 引导 RNA 的设计任务中,LOGOS 能直接根据目标 DNA 序列输出最佳 gRNA 候选,而无需分段拼接,生成效率提升逾 60%。
产业落地:从药物发现到具身智能的“科学底座”
LOGOS 的工程化能力已在多个场景得到验证。在药物研发领域,基于 LOGOS 的“序列到化合物”方案被应用于头部药企的先导化合物筛选,将传统数月的虚拟筛选压缩至数小时。在具身智能领域,科研团队利用 LOGOS 的多模态理解能力为机器人设计新型柔性材料,通过自然语言描述材料属性,模型直接生成候选晶体结构。阿里云还推出了针对自动驾驶和智能硬件的科学数据标注服务——基于 LOGOS 的语义标签系统,可将图像标注准确率提升 50% 以上。正如谷歌前 CEO 施密特所言,开源的中国大模型正在重塑全球技术格局,而 LOGOS 的横空出世,意味着科学智能的“平民化”时代已经到来。