阿里千问发布全模态大模型 Qwen3.5-Omni,无缝理解文本、图片、音频及音视频输入

核心架构与发布概述
阿里巴巴Qwen团队于2025年12月9日发布了新一代原生全模态大模型——Qwen3-Omni-Flash-2025-12-01(通常简称为Qwen3.5-Omni)。作为Qwen3-Omni的全面升级版,该模型采用了先进的原生端到端架构,旨在实现“声形意合,令出智随”的极致交互体验。不同于以往的拼接式多模态方案,Qwen3.5-Omni能够无缝处理文本、图像、音频和视频等多种输入形式,并能通过实时流式响应技术,同步生成高质量的文本与自然语音,极大地提升了交互的流畅度与响应速度。
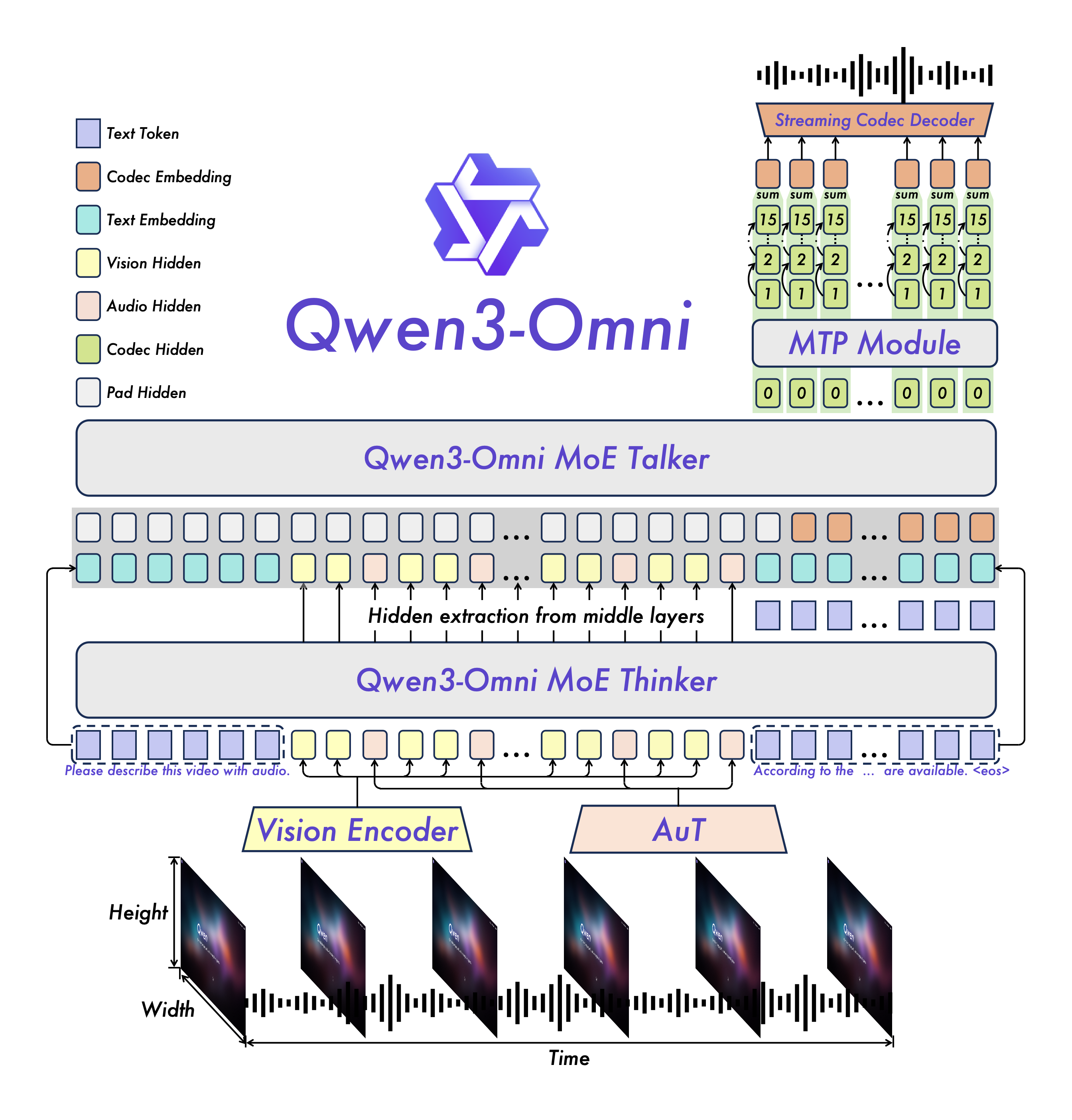
全面进化的多模态交互能力
此次升级在多模态交互的细腻度和稳定性上取得了显著突破:
- 口语化理解增强:针对口语场景中常见的“降智”问题,新模型大幅增强了对音视频指令的理解与执行能力,显著提升了多轮对话的稳定性与连贯性。
- 语音合成拟人化:彻底解决了以往语音生成中语速拖沓、机械呆板的现象。模型能够根据文本内容自适应调节语速、停顿与韵律,其语音表现的自然度与拟人化程度已逼近真人水平。
- 复杂指令遵循:在逻辑推理(ZebraLogic +5.6分)、代码生成(LiveCodeBench-v6 +9.3分)及多学科视觉问答(MMMU +4.7分)等客观性能指标上展现出强大的统治力,表明其不仅能准确“看懂”图像与视频,更具备深度的逻辑分析能力。
开放的System Prompt与自定义人设
Qwen3.5-Omni引入了飞跃性的系统提示(System Prompt)控制能力,Qwen团队全面开放了相关自定义权限。用户不再局限于通用回复,可以根据需求精细调控模型的行为模式,设定诸如“甜妹”、“御姐”或“日系”等特定人设风格,也能调整口语化表达偏好及回复长度。模型能精准执行这些设定,为用户提供高度定制化、具象化的AI陪伴与服务体验。
强大的多语言支持与普惠开放
为了满足全球化与多样化的应用需求,该模型在多语言能力上表现更加可靠。它支持119种文本语言交互、19种语音识别语言以及10种语音合成语言,确保在跨语言场景下依然能够保持准确一致的响应。目前,Qwen3-Omni-Flash已在阿里云百炼平台开放体验,企业级调用成本低至0.0018元/千Token起,致力于让高性能的全模态AI能力触手可及。