Claude降智实锤了,还变相涨价,Opus跌下神坛

背景:Claude一直是AI模型中的“高智商代表”
Claude 系列模型自发布以来,以其高推理能力、低幻觉率和良好的对话体验广受好评。尤其是 Opus 版本,被认为是目前市面上最强大的通用AI模型之一,广泛应用于编程、内容创作、数据分析等领域。
然而,近期多位用户在社交媒体和技术论坛上反馈,Claude Opus 4.6 的表现明显不如从前,推理深度下降、回答质量缩水,甚至出现频繁“无中生有”的幻觉问题。与此同时,Token 成本悄然上升,引发了“降智+变相涨价”的质疑风暴。
降智实锤:推理深度与准确率双双下滑
根据一位用户发布的详细分析报告,她收集了 6852 份 Claude Code 的会话文件、17871 个思考块、234760 次工具调用,得出了以下结论:
- 从今年 2 月起,Claude 的推理深度出现可测量的下降。
- 模型行为从“先研究再动手”转变为“先动手再说”。
- 更多“最简修复”行为,即尝试用最短路径解决问题,而不是全面分析。
她采用的核心指标是“读写比”,即模型在修改文件前读取相关文件的次数。结果显示,Claude 在多个测试轮次中,读取行为明显减少,表明其思考过程变得肤浅。
此外,BridgeBench AI 发布的幻觉排行榜截图显示:
- 上周测试中,Claude Opus 4.6 准确率为 83.3%,排名第二。
- 4 月 12 日重测时,准确率下降至 68.3%,排名第 10。
- 幻觉发生率增加了 98%,被广泛认为是“降智实锤”。
尽管 BridgeBench 的测试方法被指未控制变量,但用户仍普遍认为 Claude 的表现确实出现了退化。
Anthropic回应:不是降智,而是优化与调整
面对“降智”指控,Claude Code 负责人 Boris Cherny 在 X 上回应称:
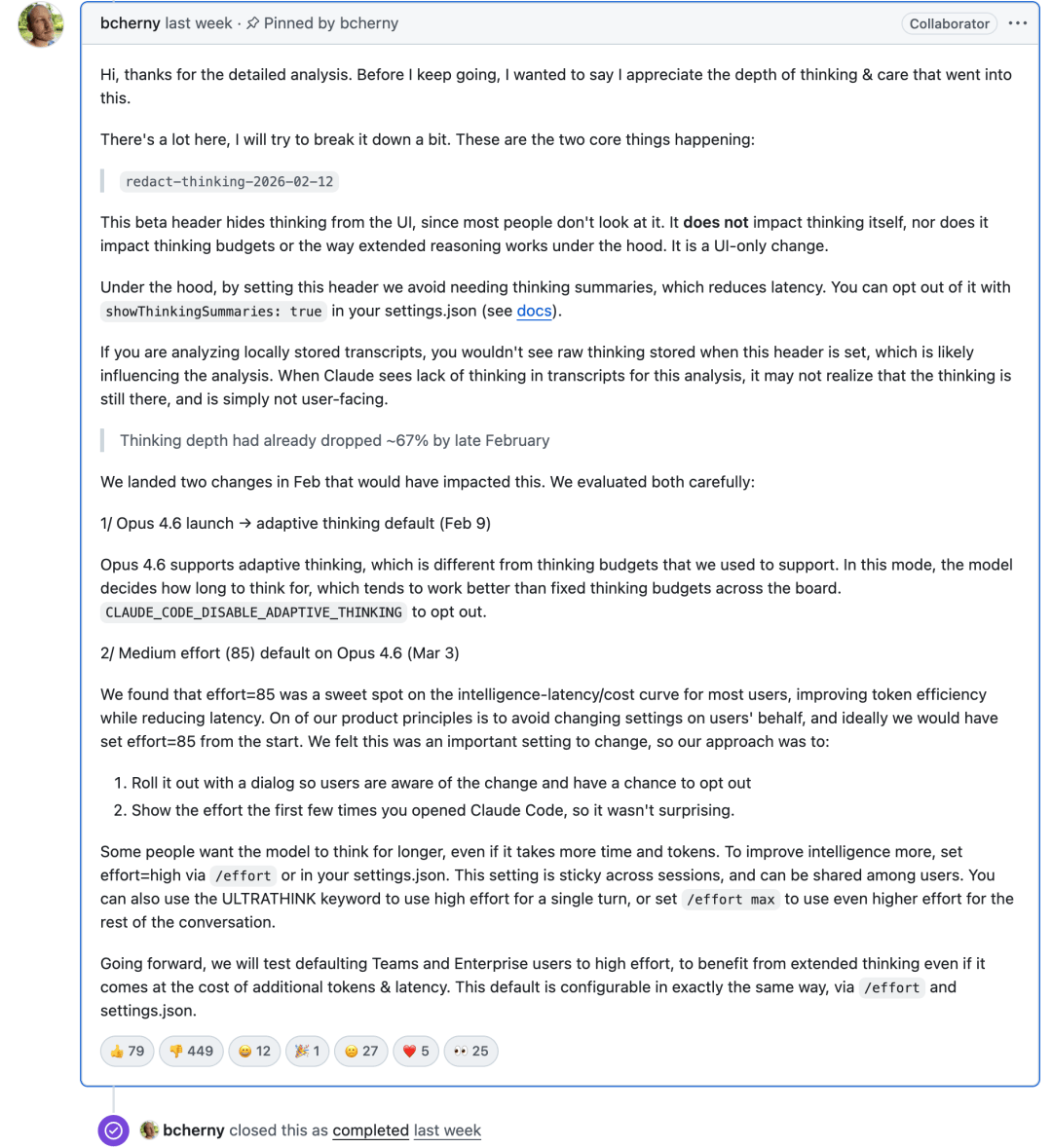
- 所谓的推理深度下降,并非有意削弱模型。
- 主要是减少思考延迟,提升用户体验。
- 用户若希望获得更高推理深度,可通过设置
/effort high和跨对话保持来实现。
另一位团队成员 Thariq Shihipar 也参与了回应,强调他们不会故意降低模型性能,并指出相关改动都已记录在 changelog 中。
但用户并不买账,他们质疑:
- 如果是优化,为何不在更新前明确告知?
- 为何改动后反而导致 Token 使用量上升?
- 模型变得不可靠,是否意味着服务质量下降?
更早前,Anthropic 曾回应过类似问题,称是底层基础设施的 Bug导致性能波动,已进行修复。但此次问题显然更具持续性和系统性。
变相涨价:Token消耗增加,成本上升
除了“降智”,用户还指出 Claude 的 Token 消耗明显增加,尤其是在长对话或复杂任务中。
根据 API 调用数据:
- 3 月初,Claude Code 的提示词缓存有效期从 1 小时悄悄缩短至 5 分钟。
- 这意味着用户每次交互都需要重新加载上下文,造成缓存频繁失效。
- Token 成本随之上升,实际使用费用变相增加。
这一改动的官方解释是为了减轻大量并发会话带来的存储压力,释放资源给更多用户使用。但用户普遍认为:
- 缓存缩短应提供可选配置,而非一刀切。
- 成本上升与性能下降并行,令人难以接受。
用户情绪与行业影响:Opus不再“神坛”
不少用户表示:
- “以前 sonnet 像智障,现在 opus 比 sonnet 还笨。”
- “付了更贵的费用,结果用上了缩水版。”
这些声音反映出用户对 Anthropic 的信任危机。Claude 曾被视为 OpenAI 之外最有竞争力的模型,尤其在企业级应用中被寄予厚望。如今却因性能与价格的双重打击,陷入舆论风波。
此外,行业观察者开始质疑 Anthropic 的更新策略:
- 是否为了快速迭代而牺牲了稳定性?
- 是否存在“借优化之名,行降智涨价之实”的营销手段?
虽然官方强调这些更新是“正常迭代”,但在用户眼中,Opus 的“神坛地位”已经动摇。
总结:AI模型的“稳定性”问题不容忽视
Claude Opus 4.6 的争议事件提醒我们:
- 用户对模型性能变化极其敏感。
- 模型“隐性改动”必须透明化,否则可能引发信任崩塌。
- AI 公司在追求技术进步与用户体验的同时,应重视服务质量的一致性。
此次“降智+涨价”风波或许只是 Anthropic 的一次“优化失误”,但也为整个行业敲响警钟:模型迭代需谨慎,用户才是真正的裁判。