打破代码大模型训练瓶颈:MicroCoder将算法数据框架训练经验升级

针对最新推理模型训练中遇到的数据难度不足和输出长度失控这两个核心瓶颈,研究团队设计了MicroCoder-GRPO算法、构建了MicroCoder-Dataset数据集、开发了MicroCoder-Evaluator评估器,并沉淀了34条跨维度的训练洞察。
算法创新:MicroCoder-GRPO与长输出潜力的解锁
在强化学习训练算法层面,研究团队发现传统方法在处理最新一代推理模型时存在明显的局限性。为此,MicroCoder-GRPO提出了一系列针对性的改进措施,旨在平衡训练稳定性与模型的长输出能力。
- 条件截断掩码(Conditional Truncation Masking):为了解决长输出潜力的释放问题,MicroCoder-GRPO放弃了传统的“全部掩码”策略。它引入了一种精细的条件掩码机制,仅当输出满足四个特定条件(达到最大长度、答案非错误、无尾部重复序列、且为随机抽取样本)时,才执行掩码。实验证明,这一策略既避免了训练不稳定性,又显著提升了模型生成长解题路径的能力。
- 动态温度调节:输出多样性是训练收敛的关键。研究发现,模型在不同温度下最终收敛到相近的多样性水平,但若初始多样性与收敛预期偏差过大,训练容易失败。MicroCoder-GRPO提出根据模型初始输出动态确定训练温度,并发现了“先低温后高温”的分阶段调节优于全程固定温度。
- KL散度与裁剪比率调整:与传统做法不同,MicroCoder-GRPO将KL散度权重设为零,并提高了裁剪比率。移除KL散度消除了限制输出长度增长的枷锁,防止了模型性能出现“先涨后跌”的现象,从而支持了持续的性能提升。
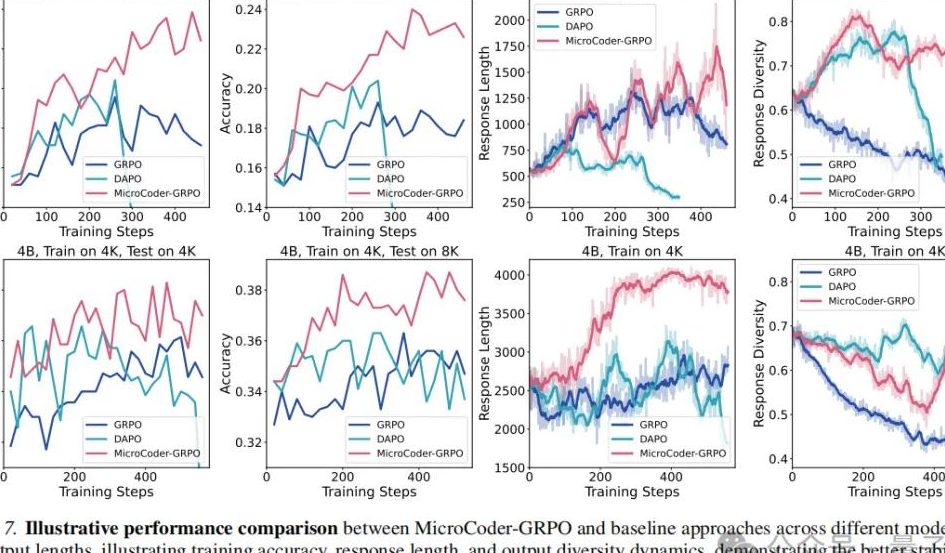
数据引擎:MicroCoder-Dataset的构建与难度筛选
数据作为模型能力的上限,其质量至关重要。针对当前主流数据集过于简单、无法满足前沿模型学习需求的问题,团队构建了MicroCoder-Dataset,该数据集包含13300个精心策划的高难度竞技编程问题。
- 四阶段处理流程:数据集构建经历“收集-处理-筛选-验证”四个阶段。不仅从多元平台收集真实竞赛题,还利用LLM进行去噪、格式标准化及测试用例生成,确保数据的可用性和准确性。
- 五维难度评估矩阵:这是数据集的核心创新。团队设计了五维评分体系,参考了Bloom教育目标分类法、McCabe圈复杂度等理论,由LLM对题目进行三次独立打分。随后,结合模型实际通过率进行校准,确保筛选出的题目真正考验推理与编程能力。
- 显著的性能提升:过滤后,简单题占比降至25%以下,困难题占比提升至50%以上。在相同训练条件下,使用MicroCoder-Dataset获得的性能增益是DeepCoder数据集的3倍,尤其在高难度题目上的提升最为明显。
评估框架:MicroCoder-Evaluator提升反馈精度
训练评估器的精度直接影响模型的学习方向。传统的精确匹配策略常因格式或浮点数精度问题将正确的解法判为错误,产生噪声干扰训练。
- 高容错回退链:MicroCoder-Evaluator采用由6-7种方法组成的回退链进行验证。它支持列表、元组、字符串等格式的自动类型转换,进行浮点数近似比较,并进行多行分割与空白规范化处理。当一种方法失败时,自动尝试下一种,在保证严谨性的同时极大提升了容错率。
- 效率与准确率的双重提升:相比原版LiveCodeBench评估器,MicroCoder-Evaluator将评估准确率提升了约25%,有效识别了正确解法的变体。同时,通过优化并行策略,其执行速度提升了约40%,显著提高了训练效率。
训练经验沉淀:跨越代际的认知升级
MicroCoder项目不仅贡献了工具和数据,更在代码大模型训练的范式认知上实现了突破。
- 代际断层的认知:研究明确指出,最新推理模型的训练动态与旧模型存在质的区别。简单数据已无法驱动前沿模型的进步,而旧有的训练方法(如固定的温度、保留KL散度)在新模型上甚至会产生反效果。
- 34条开源训练洞察:团队通过超过30组受控实验,总结了覆盖算法、数据、评估、上下文、温度等7大维度的34条训练经验,并在GitHub上开源。这些经验揭示了诸如“早期上下文长度限制会产生不可逆影响”、“较小批大小有利于多样性但牺牲稳定性”等重要发现,为新一代代码模型的研究指明了方向。