北大联合Llama-Factory推出DataFlex:工业级数据动态训练系统

背景与发展动因
近年来,随着大模型的快速发展,训练过程中对数据管理与调度的需求日益复杂。传统静态数据训练方法在效率、灵活性与扩展性方面已难以满足工业级大模型训练的高要求。为解决这一瓶颈,北京大学与LLaMA-Factory团队联合推出了名为DataFlex的新型数据动态训练系统。该系统旨在通过动态调整数据策略、提升训练效率,为大模型训练提供更具弹性与智能的数据支持。
DataFlex的设计目标主要聚焦于以下几个方面:
- 提升训练效率:动态调度数据,减少训练过程中的资源浪费。
- 增强数据灵活性:支持多种数据策略的实时切换与融合。
- 工业级可扩展性:面向大规模训练场景,确保系统稳定与高效运行。
核心架构与功能特性
DataFlex采用了三层模块化架构,确保系统的高效性与可扩展性:
-
基础层
完整继承LLaMA-Factory的成熟模型管理、数据处理和训练组件,保证系统的稳定性与兼容性。 -
训练器层
提供三大专用训练器,分别用于:- Select(选择):根据模型训练阶段动态筛选合适的数据集。
- Mix(混合):融合不同数据源与策略,提升模型泛化能力。
- Weight(加权):对数据进行加权处理,强化关键样本的学习效果。
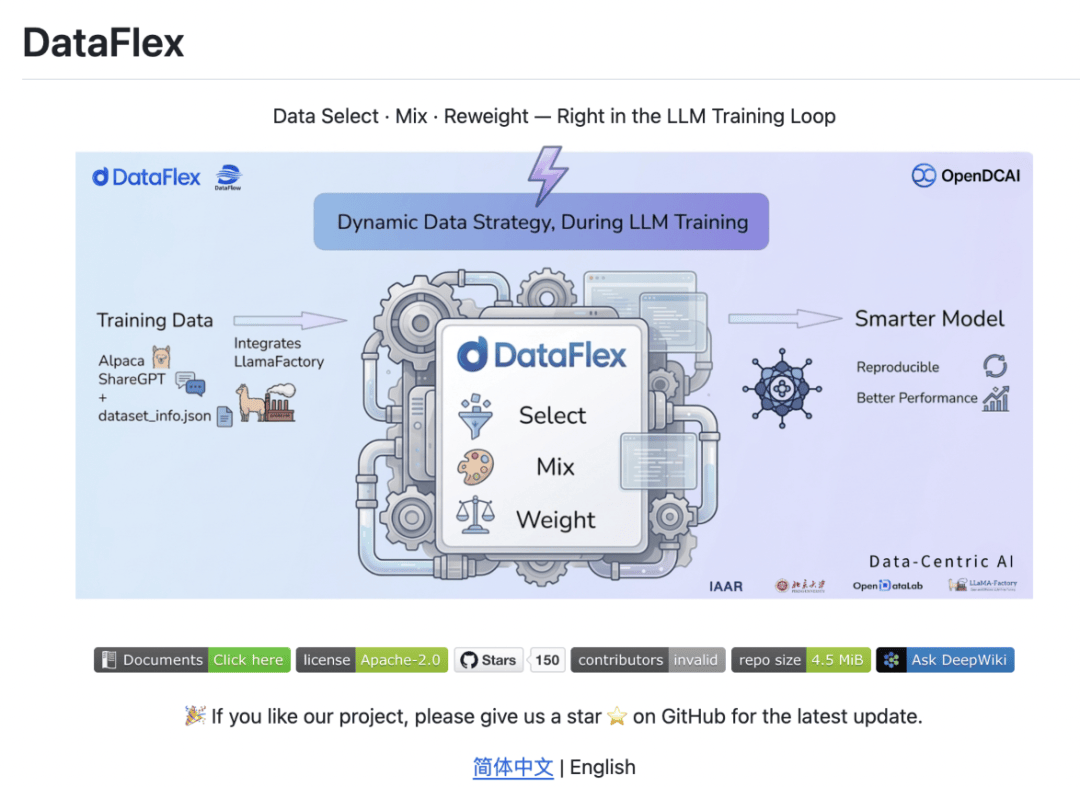
- 组件层
封装了可插拔的算法模块,开发者只需完成模块注册即可快速接入系统,便于研究与工程团队快速验证和部署新方法。
此外,DataFlex在训练层引入了统一的数据中心控制能力,使不同数据策略可以协同调度,提升了整体系统的灵活性和响应速度。
技术亮点与创新点
-
数据策略统一调度
系统能够统一管理多种数据策略,实现动态调整和自动化调度,适应不同训练阶段的模型需求。 -
模块化与可插拔设计
新方法的开发与集成更加高效,缩短从研究到落地的周期,降低工程化门槛。 -
训练过程智能化
借助Select/Mix/Weight训练器的组合,模型训练可以自动识别高质量数据、平衡学习分布,避免过拟合或训练偏差。 -
工业级稳定性支持
针对大规模分布式训练进行优化,具备良好的扩展性和容错机制,适合在企业级AI系统中部署。
应用前景与行业影响
DataFlex的推出标志着AI模型训练正从“模型为中心”向“数据与模型协同进化”迈进。该系统有望在以下场景中发挥关键作用:
- 大模型持续预训练与微调:支持动态更新数据源,适应不断变化的训练目标。
- 多任务学习:通过Mix训练器融合多个任务数据,提高模型多模态、多功能能力。
- 个性化训练场景:在医疗、金融等垂直领域中,实现针对特定数据分布的定制化训练策略。
这一系统的开源与推广将为AI训练提供新的基础设施,进一步降低训练成本,提升训练质量,推动大模型技术在产业界的广泛应用。
合作与未来展望
此次合作由北京大学与LLaMA-Factory团队共同完成,体现了高校与开源社区在前沿AI技术探索中的深度联动。未来,团队计划继续扩展DataFlex的功能,包括支持更多类型的数据格式、增强数据质量评估模块,以及引入强化学习机制优化数据调度策略。
同时,DataFlex也将与更多AI平台和框架进行集成,提升其生态兼容性与工业适用性,助力构建更加高效、智能的大模型训练流程。