大模型的有脑和无脑

背景介绍
- 大模型(Large Language Model,LLM)是当前人工智能技术发展的核心趋势之一。
- 它们通常由深度神经网络构建,参数数量可达到数十亿甚至数千亿。
- 这类模型能够处理自然语言、图像、音频等多种信息,展现出类似人类的推理、生成和决策能力。
- 在这个过程中,一些观点认为它们已经具备了“有脑”的特征,而另一些则强调它们仍缺乏真正的智能核心。
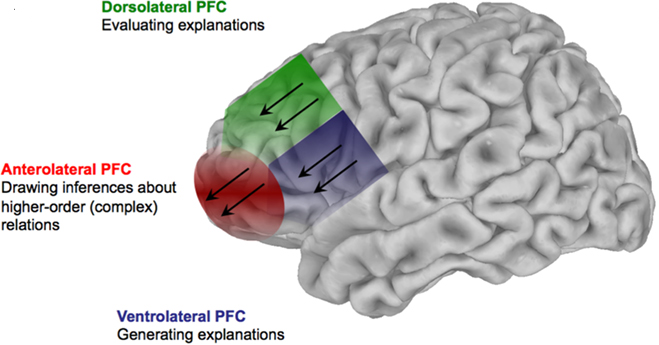
大模型的“有脑”特性
- 感知与交互能力:大模型通过海量数据训练,获得了理解用户意图、回应复杂问题的能力。
- 决策能力:它们可以进行逻辑推理、生成内容甚至在特定任务中优化策略,展现出类人智能行为。
- 个性化输出:后天的数据训练类似于人类经历,对模型行为进行“二次改造”,使其输出更具个性。
- 产业重塑潜力:专家认为,智能体以大模型为基础,可能催生新的产业模式和业务生态。
大模型的“无脑”局限
- 缺乏自主意识:尽管大模型能够模仿人类语言和思维过程,但它们并不具备真正的意识或理解能力。
- 依赖数据输入:模型的表现完全取决于训练数据的质量和范围,没有“独立思考”或“创造”能力。
- 无情感和伦理判断:大模型在处理问题时不会考虑情感因素或道德价值,可能生成偏见或不合适内容。
- 决策不具备因果性:它们是基于统计和模式匹配进行预测和生成,而不是基于因果推理。
技术与哲学视角的争论
- 有观点认为,大模型的“系统设定”类似于人类的“本能”,但缺乏情感和主观能动性。
- 也有研究者认为,随着技术的发展,大模型可能在未来具备更接近人类大脑的特性。
- 当前技术更偏向于“工具化智能”,即大模型是增强人类能力的工具,而非独立智能体。
- 这场“有脑”与“无脑”的争论不仅关乎技术能力,也涉及对智能本质的哲学思考。
未来发展趋势
- 随着算力提升和算法优化,大模型将越来越逼近人类语言和思维的边界。
- 智能体的发展可能让大模型具备更全面的感知和行动能力,进一步模糊“脑”的定义。
- 需要建立更完善的人工智能伦理与监管体系,以应对模型在社会中的深远影响。
- “有脑”与“无脑”的界限可能在未来变得模糊,甚至被重新定义。