最高降价 99%,小米 MiMo 首次公开模型推理系统全链路优化技术细节

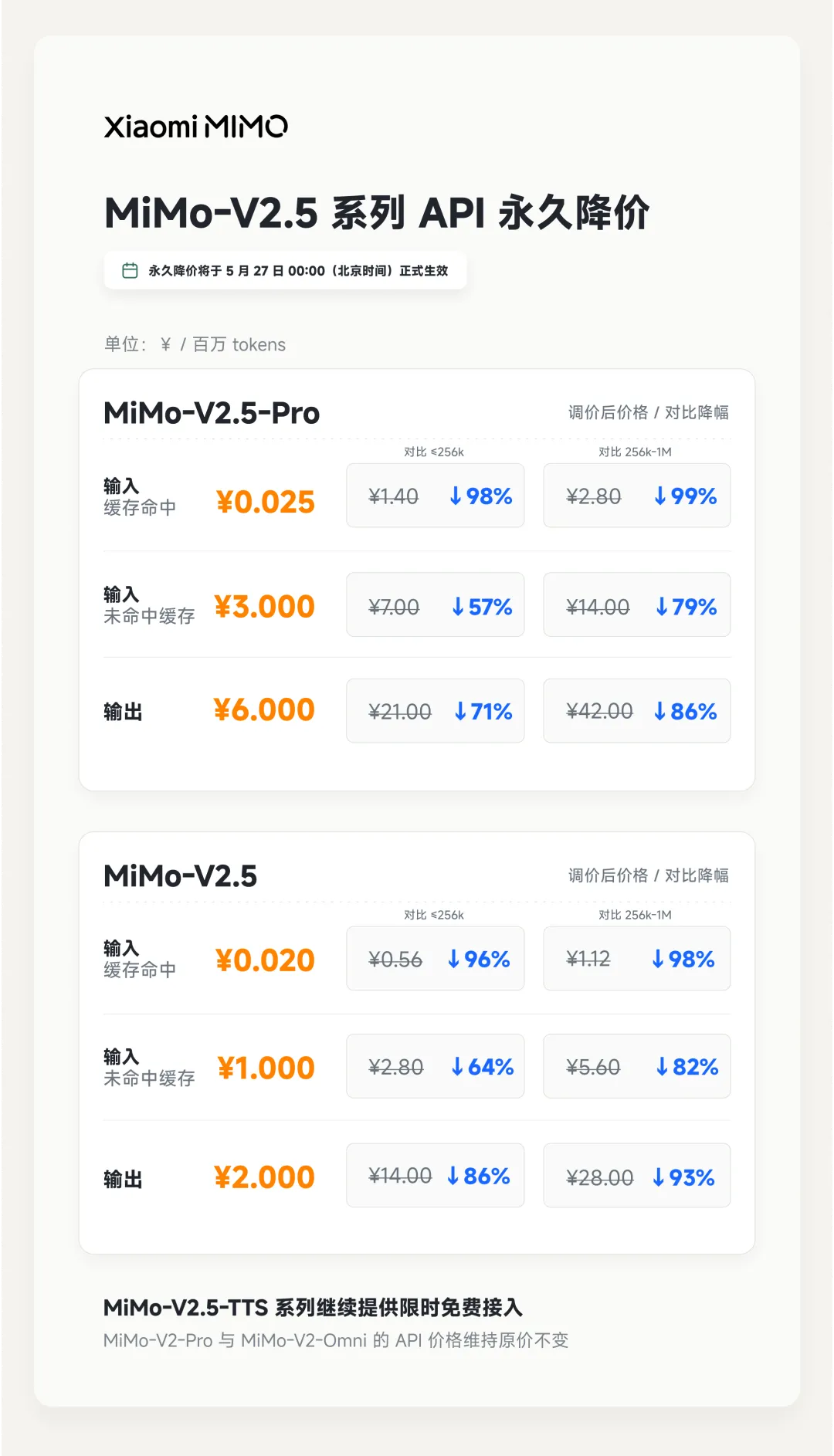
雷军宣布“价格屠夫”行动:MiMo-V2.5系列API永久降价99%
5月27日一早,小米创始人雷军在微博宣布,旗下MiMo大模型对V2.5系列API进行永久性大幅调价,最高降幅达到99%,且不再区分上下文窗口长度。同时,Token Plan计费体系也同步优化,采用“加量不加价”策略:在Agent或Code场景下,用户可用Token数量提升至原来的5-8倍,并将计价规则调整为“所见即所得”,彻底简化了因上下文换算导致的复杂逻辑。对比国际主流模型,OpenAI GPT-4o标准输入价格为每百万Tokens 2.5美元,输出10美元;Claude Sonnet 4.6输入3美元,输出15美元。小米此举被业界视为“价格屠夫”式进攻,试图通过极低成本构建生态壁垒。
缓存技术颠覆:KV Cache搬运量降至1/7,可缓存Token飙升5倍
降价的底气源于MiMo推理系统的全链路优化。小米技术团队公开了关键细节:基于SGLang HiCache框架,完整支持SWA(滑动窗口注意力机制),将KV Cache在GPU显存、CPU内存、SSD等多级存储之间的数据搬运量降低至优化前的近1/7。这一突破意味着推理过程中原本需要频繁跨设备搬运的缓存数据大幅减少,同时可缓存的Token数量提升至近5倍,显著提高了缓存命中率。优化后,同等硬件条件下的单次推理成本被成倍压缩,为降价99%提供了直接技术支撑。
专家方案与分桶策略:集群输入吞吐能力跃升
除了缓存链路优化,小米还通过多个工程手段提升集群整体效率。具体包括:
- 优化专家(Expert)方案:针对MoE架构中的专家路由,重新设计负载均衡与激活策略,减少冗余计算。
- 输入长度分桶策略:根据用户请求的实际Token长度进行分桶处理,避免长尾请求拖累整体吞吐,使集群在面对混合场景时保持高利用率。
这些手段共同提升了集群的输入吞吐能力,在不增加硬件投入的前提下,将单位Token的算力成本进一步压低。
从“聊天”到“干活”:低价背后的生态野心与行业变局
本轮降价并非偶然。大模型正从对话式应用进入Agent、自动化工作流等“干活”阶段,开发者焦虑的已不再是单次问答费用,而是多轮推理、调用和自动化流程中持续燃烧的Token。小米通过极致降价,意图将Token价格打造成类似电力一样的底层基础设施成本——即“AI时代的电价”。低价策略背后,是更高的推理效率、更强的算力调度能力,以及长期生态投入的决心。对于开发者而言,成本骤降意味着Agent等应用供给将迎来井喷;而对于整个行业,当百万Token价格被不断压低,竞争将向下游传导至应用层与生态层。