过程比结果重要:一个不给标准答案的调参框架,让Agent自己把数据库性能榨出来

传统调参陷入“手工作坊”困局
数据库调参一直是运维人员最头疼的难题——数百个参数交织影响,最优配置往往取决于业务负载、硬件特性和数据分布,没有“标准答案”可抄。正如数据库领域图灵奖得主Mike Stonebraker指出的,现代系统的复杂性已经远超人工经验所能覆盖的范围。依赖人肉试错不仅低效,更难以复现,Agent开发光谱中的“原始代码”阶段恰恰映射了这种状态:开发者直接调用API、手动管理状态,从零开始构建一切,而调参过程同样停留在“猜参数重要程度”的野蛮摸索中。IBM Research发布的Agentic CLEAR工具则警示,Agent执行过程若缺乏透明监控,连“哪里出了问题”都难以定位,更不用说主动优化了。
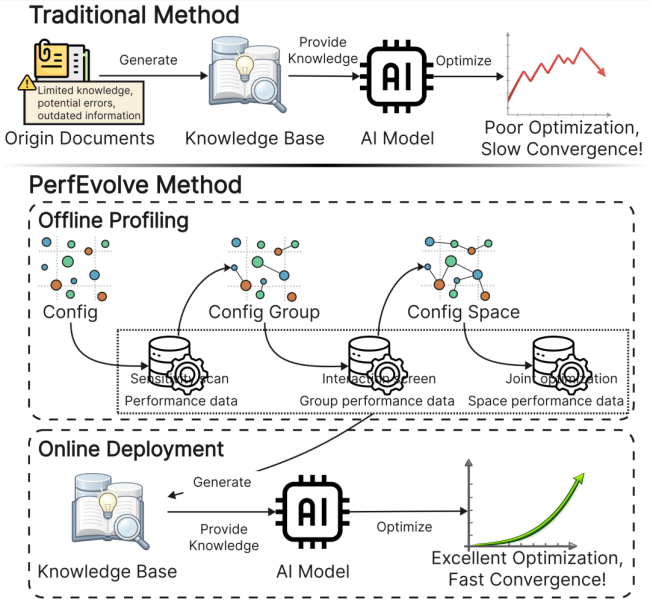
PerfEvolve的破局:先测重要性,再让Agent自己跑
面对标准答案的缺失,新框架PerfEvolve选择换个思路:它不要求Agent猜测哪些参数重要,而是通过性能分析(profiling)提前把参数的实际影响测出来。类似于上下文工程中“结构化对抗熵增”的逻辑——先用元信息标记“这段数据从哪里来、有什么用”——PerfEvolve将调参过程显式分解为两步:首先生成数据库运行时的关键画像,明确每个参数对吞吐量、延迟的边际贡献;然后交给Agent一个动态搜索空间,让它在已量化的重要性指导下自主探索。这种“不给答案只给地图”的方式,把调参从黑箱试错变成可追溯的迭代过程,Agent不再需要天马行空地胡乱猜测,而是沿着profiling给出的等高线稳步爬山。
过程监控:从“瞎蒙”到“可追溯”的认知飞跃
Agent在调参过程中需要持续反馈。参考资料中Agentic CLEAR的设计思想被引入:它能够自动记录Agent的每一步操作、决策依据和中间结果,让用户像看日志一样回溯整个调参链路。这个机制与L3语义记忆中的知识图谱思路不谋而合——通过实体-关系-实体三元组,系统不仅能知道“最终选择了什么配置”,还能理解“为什么选择这个值”。PerfEvolve结合了类似的监控能力,Agent的每一次参数试探、性能变化都会被结构化存储,形成可复用的调参经验库。这彻底改变了“调完就丢、下次重来”的窘境,让Agent自身也在过程中积累“手感”,实现从一次性优化到持续学习的跃迁。
新范式启示:让Agent自己学会“怎么学”
PerfEvolve背后的哲学呼应了AI系统构建中的深层趋势:相比直接给模型注入知识(如RAG的实时检索或微调的能力学习),更重要的或许是教会模型“如何获取知识”。参考资料中RAG与微调的对比清晰地表明,当需要频繁更新领域知识(比如数据库参数的最新特性)时,RAG是更优选择——它不改变模型参数,而是通过检索外部信息来动态适应。PerfEvolve正是这种思想的调参版:它不试图固化一套“最佳配置”到Agent内部,而是通过动态profiling和监控反馈,让Agent在每个运行环境中自主发现新规律。这种“过程导向”的工程哲学,从数据库调参蔓延到AI系统的方方面面,预示着下一阶段Agent将从“执行预设脚本”走向“主动探索未知”。