基于Gemini 1.5长上下文能力,谷歌对话式医疗系统AMIE在100例多次就诊场景中达到全科医师的推理水平

虚拟诊室大比拼:100个案例,5个专科,AMIE对阵21名医生
为了检验AMIE的实际临床推理水平,谷歌团队设计了一项严格的虚拟临床检查研究。他们构建了100个多就诊案例场景,覆盖5个医学专科领域,这些场景严格参照英国国家卫生与临床优化研究所(NICE)的指导意见及《英国医学杂志》最佳实践指南。研究招募了21名全科医生,在与AMIE相同的条件下进行管理推理任务。结果显示,在管理推理能力这一核心指标上,AMIE的表现与真实全科医生不相上下,首次证明了基于长上下文的大语言模型可以胜任连续多次就诊的临床管理推理。
精准度与指南遵循度双超人类:AMIE的多项关键指标更胜一筹
不仅达到医生水平,AMIE在部分维度上甚至实现了超越。研究数据显示,在治疗和检查的精准度上,AMIE的表现优于参与测试的医生。更重要的是,它对临床指南的遵循程度极高,基于指南制定管理方案的合理性同样超过了医生。此外,在最新推出的药物推理基准上,AMIE在处理疑难病例时的表现也优于人类医生。这意味着AI不仅能“像医生一样思考”,还能更严格地遵循标准化临床路径,减少人为偏差。
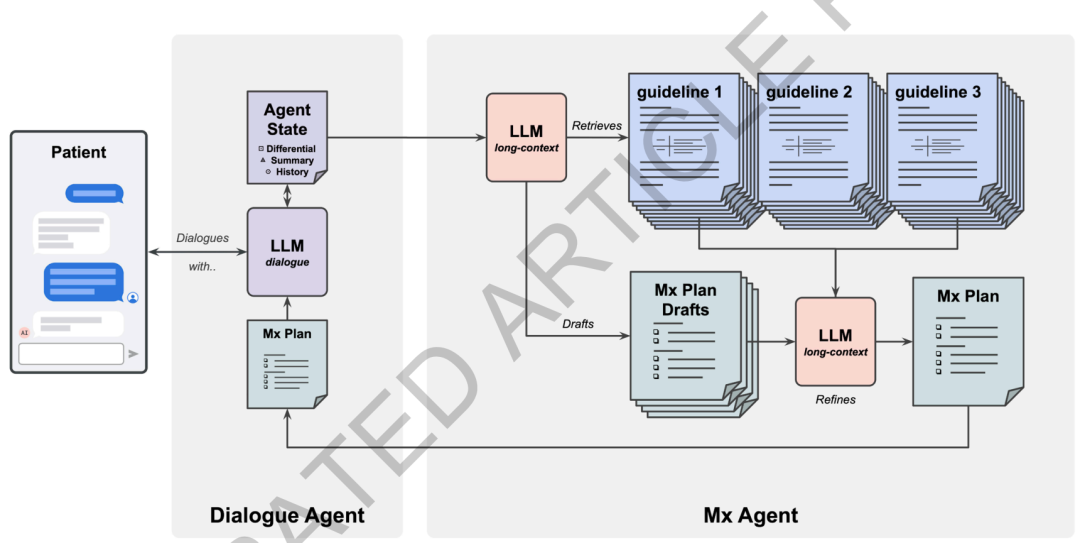
长上下文与自演循环:AMIE的“学习秘籍”如何炼成
AMIE的核心优势来自于谷歌Gemini 1.5模型的长上下文能力,使其能够对多次就诊数据进行连续推理,从而追踪疾病进展和治疗反应。为了优化这种对话能力,谷歌开发了一种创新的“自我对话模拟学习环境”,包含两个循环:内部循环中,AMIE与AI患者模拟器对话,并利用自动化反馈不断改进;外部循环则将优化后的对话纳入后续微调迭代。这种基于“自演博弈”的方法,让AMIE在模拟环境中快速积累经验,并引入链式推理策略,确保每一步答复都基于当前对话情境逐步推导。
从实验室到临床:对话式AI辅助医疗迈出关键一步
虽然AMIE目前仍是一个研究原型,尚未投入实际临床护理,但这项研究被《自然》期刊评价为“标志着利用对话式人工智能工具辅助医生进行疾病管理迈出了重要一步”。谷歌团队强调,AMIE的设计初衷是“探索可能性的艺术”,旨在展示AI系统未来能达到熟练临床医生的能力。后续还需进一步研究其在现实世界限制下的表现、健康公平性、隐私保护等关键问题,但AMIE在虚拟场景中与全科医师相当的推理水平,已为全球部分地区缓解医生短缺问题提供了极具潜力的技术路径。