基于Gemini 1.5长上下文能力,谷歌对话式医疗系统AMIE在100例多次就诊场景中达到全科医师的推理水平

AMIE如何炼成自我博弈的医学对话大脑
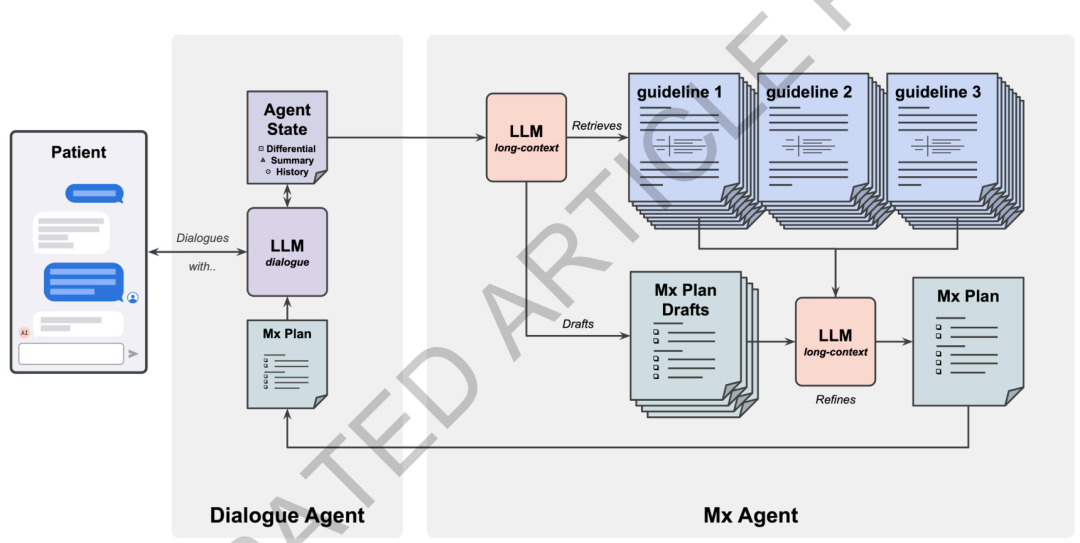
为了培养能像资深全科医生一样“问诊”的AI系统,谷歌研究团队创造了一套独特的训练方法。AMIE的核心并非简单的问答模型,而是一个经过深度优化的对话式诊断引擎。研发人员引入了基于“自我对话”的模拟学习环境:让AMIE与一个AI患者模拟器进行内部对弈,通过自动化反馈机制不断修正提问策略;随后将改进后的对话注入外部微调循环,形成持续进化的良性螺旋。这一过程使AMIE能够应对149种不同专科和疾病的场景,并且在推理时采用链式策略,逐步缩小不确定性范围——就像医生在反复追问中锁定病因。
149场模拟会诊:AI医生的诊断准确率全面超越
在一项随机双盲交叉研究中,20名获得认证的初级保健医师与AMIE通过文本聊天界面与专业演员扮演的“标准化患者”进行对话,涵盖加拿大、英国和印度OSCE提供商的149个病例。从专科医师和患者两个角度评估,AMIE在绝大多数指标上胜出:专科医师评定的32个维度中,AMIE在28个维度得分更高,包括诊断准确率、病史采集和共情表达;从模拟患者视角看,26个维度中有24个更青睐AMIE。尤其值得注意的是,AMIE的前10鉴别诊断准确率达到59.1%,远超未受辅助的人类医师(33.6%)。即使在多次就诊、多轮对话的复杂场景下,AMIE的推理逻辑仍保持与全科医师相当的水平。
从文本到影像:Gemini长上下文赋予AMIE多模态推理
AMIE的能力并未止步于文字。借助Gemini 1.5架构的长上下文支持,AMIE进化出“看见”医疗影像的能力。研究团队将Gemini 2.0 Flash作为新核心大脑,结合状态感知推理架构,使AMIE能动态整合患者上传的皮疹照片、心电图扫描等视觉信息。在105种医疗情境的模拟OSCE测试中,具备多模态理解能力的AMIE在诊断准确性和处置计划合理性上均超越人类初级保健医生,且初代Gemini 2.0向2.5的升级进一步提升了Top-3诊断准确率。长上下文让AMIE不仅能回顾单一就诊中的全部对话,还能关联多次就诊的变化——这对慢性病管理、复诊追踪等“多次就诊场景”至关重要。
未来诊断AI:不等于替代医生,而是赋能临床
尽管AMIE表现惊艳,谷歌团队反复强调这仍是早期实验探索,并非成品。研究揭示了长上下文AI在医疗中的巨大潜力:有望填补全球初级保健医生短缺的空白,提升医疗服务可及性和一致性。但现实挑战同样严峻——真实临床环境中的噪声对话、健康公平性、隐私保护以及AI的“幻觉”风险都需要更严谨的研究。正如论文所述,AMIE更像是“探索可能性的艺术”,其最终目标是成为医生和患者的良好沟通伙伴,而非替代者。未来,持续迭代的Gemini长上下文模型或许能帮助AI系统真正理解患者五年辗转求医的完整病史,让Greg Brockman口中的“整体诊断”愿景成为现实。