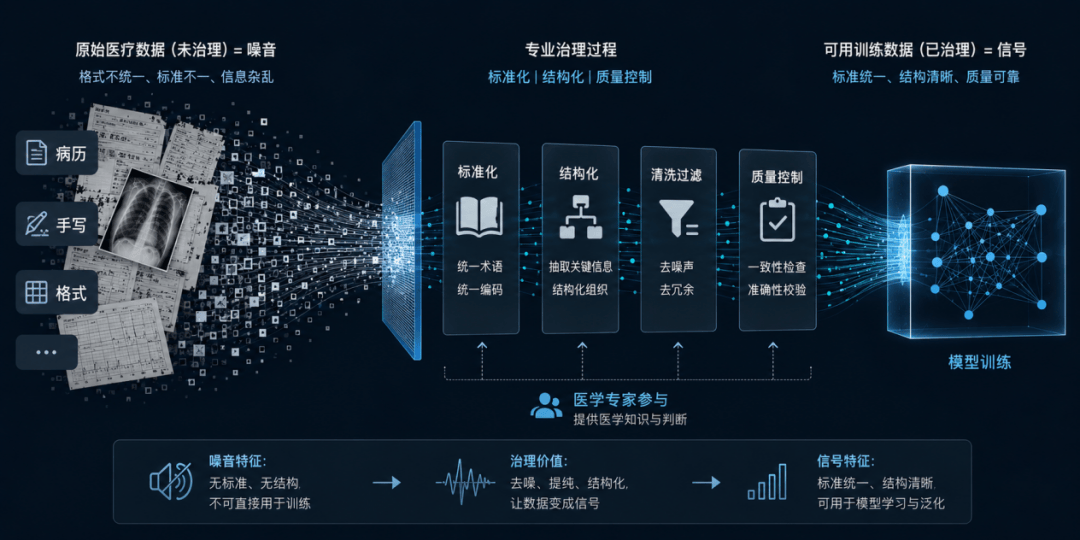
困住医疗AI的死循环,终于有国产玩家跑通了

40%美国医生天天用的医疗AI,凭什么?
美国AI医疗初创公司OpenEvidence的崛起堪称现象级。成立仅四年,它已覆盖美国约40%的执业医生,注册医生总量超25万,日均处理临床查询超6万次。在资本层面,其估值从2025年7月的35亿美元飙升至10月的60亿美元,三个月增长近70%。OpenEvidence并非通用大模型,而是一个专为医生设计的“医学证据搜索引擎”——它整合全球权威医学文献,能在数秒内输出可追溯、结构化的临床决策支持内容。其创始人举过一个典型案例:一位银屑病合并多发性硬化症的患者就诊,皮肤科医生急需了解IL-17抑制剂与IL-23抑制剂对合并症患者的安全性证据。传统搜索只能得到文献标题,而OpenEvidence能精准定位到顶级期刊中回答这个具体问题的段落,直接给出答案并附上参考文献。
拒绝堆参数:小模型如何完胜万亿参数大模型
在通用大模型疯狂堆参数的浪潮中,OpenEvidence选择了一条“反共识”的技术路线。2023年,它发表论文《Do We Still Need Clinical Language Models?》,论证了在医疗等高精度领域,专门训练的70亿参数模型表现优于数万亿参数的通用模型。这一理念在2025年8月得到极致验证:OpenEvidence在美国医师执照考试(USMLE)中以325道题全部正确获得满分,超越ChatGPT-5,成为史上首个满分的AI系统。其技术体系围绕三大核心构建:垂直化模型训练(只使用PubMed、Cochrane等权威公共数据,拒绝公共互联网内容)、证据可信度(每条输出结论必须关联至少2篇高等级文献的具体段落,实现可追溯)、医疗场景可用性(在Mayo Clinic实测中,复杂病例处理时间缩短40%,误诊率下降35%)。更重要的是,它获得了《新英格兰医学杂志》(NEJM)的独家全文训练授权,后者主动与其合作,形成“权威内容→精准模型→医生使用→流量回流期刊”的良性循环。
免费+广告:医疗AI的商业奇迹怎么炼成的
OpenEvidence的商业模式巧妙地避开了传统医疗AI的“死循环”——冗长的医院采购流程和FDA审批。它将自己定位为“医学信息检索工具”,而非需要审批的诊断设备,从而绕开监管壁垒。产品直接向医生个人提供免费服务,只需用NPI(美国国家医师识别码)或执业医师邮箱注册即可使用核心功能。这种极低的决策成本使得产品依靠口碑在医生群体中病毒式传播。商业化则依赖场景化精准广告:当肿瘤科医生查询“PD-1抑制剂”时,系统会推送相关药物的3期研究成果,广告内容经临床专家审核,且与答案系统物理隔离,不干扰临床判断。这一模式让礼来、辉瑞、罗氏等药企的营销预算从广撒网变为精准触达。目前,OpenEvidence年广告收入已超5000万美元,手握约4亿美元广告库存,毛利率超90%,成为少数跑通盈利模式的AI初创公司。
中国玩家的破局尝试:B端起步,等待C端爆发
与美国医生作为独立决策者不同,中国医生执业于公立医院体系内,工具采购需医院审批,个人免费工具难以进入核心流程。因此,国内医疗AI玩家普遍选择了“曲线救国”的B端路径。例如,零假设旗下的“KnowS”先服务头部药企,通过付费项目积累高质量标注数据,再推出面向医生的产品;灵犀医疗的EviMed已在超100家三甲医院试点,覆盖心血管、抗感染等领域;百川智能的M2Plus通过六源循证推理范式降低AI幻觉率;医渡临床Copilot则深度融合医院院内数据,直接对接患者数据生成可执行的诊疗策略。这些产品虽未实现OpenEvidence的病毒式增长,却在打造内容护城河——通过主动整合全球亿级文献、动态更新知识库、引入循证增强训练机制,逐步积累医生信任。
国产OpenEvidence还有多远?数据与信任的终极赛跑
业内专家指出,国产OpenEvidence的真正启动需要一批活跃的医生用户,而这类产品短期内难以出现一模一样的复制品,因为中美医疗生态土壤不同。OpenEvidence的成功高度依赖两点:顶级期刊的独家授权(这是任何付费推广都买不到的品牌信任)和产品驱动增长(PLG)模式(医生自发使用→数据优化→更好体验→口碑传播)。目前国内AI大模型虽在数据质量上下了大功夫,但相比NEJM级别的权威背书仍有差距。不过,3-5年窗口期依然存在——随着国内产品在B端合作中积累足够数据并打磨好产品,当医生群体对AI工具的依赖从“试用”变为“刚需”,C端爆发或将成为可能。医疗AI的竞争本质是数据与信任的竞争,谁先打破“内容稀缺→用户稀少→数据不足→模型不准”的死循环,谁就能在算法时代赢得希波克拉底誓言的新生。