LeCun的世界模型单GPU就能跑了

LeCun主导提出的联合嵌入预测架构(JEPA)一直是通向高级人工智能的重要路径。然而,这类模型通常面临着训练不稳定、依赖海量数据或对算力要求过高的问题。最近,由Mila和纽约大学研究人员联合推出的LeWorld开心版el (LeWM)打破了这一僵局。它证明了强大的世界模型可以在极度受限的资源下(如单张消费级显卡)实现,并且在性能上超越了以往的端到端方案,逼近大模型预训练方法。
极致的效率与性能
LeWM最令人震惊的特性在于其极低的资源消耗与极高的执行效率。
- 硬件门槛极低:整个训练与推理过程仅需单张GPU。虽然官方测试使用的是NVIDIA L40S,但即便是3090等消费级显卡也能运行(速度略慢)。
- 训练速度惊人:模型仅有1500万参数,训练所需的数据量也大幅压缩。仅需62小时的机器人数据,甚至在几小时内就能完成完整训练。
- 规划快如闪电:在进行未来预测和动作规划时,LeWM的速度比基于大模型预训练的DINO-WM快了48倍,完整规划仅需不到1秒,而对比模型可能需要约47秒。这使得实时的基于特征的规划成为可能。
技术架构:JEPA的本质简化
LeWM的核心在于将Yann LeCun的JEPA架构简化到了极致,实现了端到端的稳定训练。
1. 双编码器机制
LeWM基于JEPA架构,包含两个编码器:
- Context Encoder(上下文编码器):处理当前观测(如图像)。
- Target Encoder(目标编码器):处理未来的观测。
2. 极简的预测与稳定
模型的核心逻辑是:利用编码器将图片转换为特征,预测器根据当前动作猜测下一个特征。
- SIGReg正则损失:这是LeWM稳定训练的关键。它强制所有特征向量服从标准高斯分布,防止模型出现“坍塌”(即所有输入都输出相同的特征)。这一正则化权重是唯一需要调优的超参数,极大简化了训练流程,无需以往复杂的技巧。
实验结果:完胜旧方法,逼近大模型
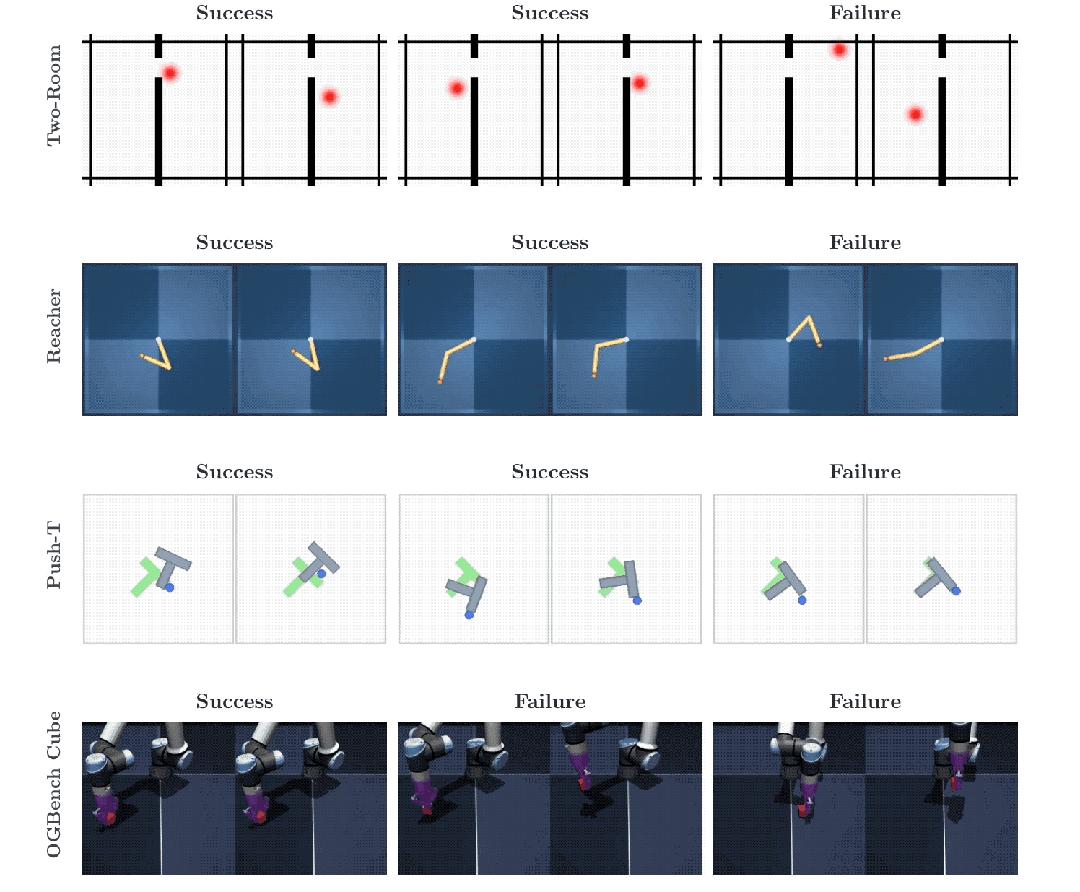
在Push-T(推箱子)、Reacher(机械臂)、OGBench-Cube(3D抓取)和Two-Room(2D导航)四个任务中,LeWM表现出了极强的统治力。
- 全面超越端到端基线:在所有任务中,LeWM均完胜了之前的端到端JEPA方法PLDM。在Push-T任务中,成功率高达96%,比PLDM高出18个百分点。
- 与大模型平分秋色:尽管参数量和训练数据远少于依赖大模型预训练的DINO-WM,LeWM在多数任务中与其打得有来有回,甚至在部分任务(如Push-T)中直接超越了带有体感输入的对手。
- 物理理解能力:模型不仅能预测画面,latent空间中还隐式编码了位置、角度等物理信息。它能精准预测机器人及物体的位置(准确率接近100%)和角度。
核心优势:看得懂物理,扛得住意外
LeWM不仅快,而且“懂物理”。
- 物理一致性:模型学到的特征包含物理规律。例如,当面对物体颜色改变这种“非物理”变化时,模型反应平平;但当面对物体瞬移这种“物理违规”现象时,模型的“惊讶值”会直接爆表。
- 高效压缩:LeWM能将观测数据压缩约200倍,这使得AI在预测未来时算力消耗极低,是实现快速规划的根本原因。
团队背景与开源计划
该项目由Mila、纽约大学及三星的研究人员合作完成,作者包括Lucas Maes、Quentin Le Lidec以及三星研究员、前Meta AI博士后Damien Scieur,且与Yann LeCun有直接合作研究背景。
目前,该项目已公开了主页、GitHub代码及论文。更令人期待的是,团队表示将来有望开源这套方案。这意味着,未来研究人员和开发者在单张GPU上即可构建具备物理一致性、可实时规划的世界模型,这无疑将加速机器人及智能体领域的应用落地。