蚂蚁灵波开源 LingBot-Map:仅用普通摄像头让机器人实现实时流式三维重建

背景与技术演进
近年来,机器人在环境感知和交互能力上的提升成为人工智能研究的核心方向之一。作为具身智能的重要组成部分,三维空间重建技术长期以来依赖昂贵的传感器和复杂的计算架构,限制了其在消费级设备上的广泛应用。
蚂蚁灵波作为具身智能领域的新兴力量,持续发布多项关键技术成果,涵盖机器人“眼睛”、“大脑”和“世界模型”等多个层面。继LingBot-Depth(空间感知模型)和LingBot-VLA(具身操作模型)之后,其最新开源的LingBot-Map模型,进一步降低了三维重建的硬件门槛,实现了基于普通摄像头的实时流式三维建模能力。
LingBot-Map的核心技术特点
LingBot-Map是一款基于普通摄像头的轻量级三维重建模型,其核心优势在于高效性和实时性:
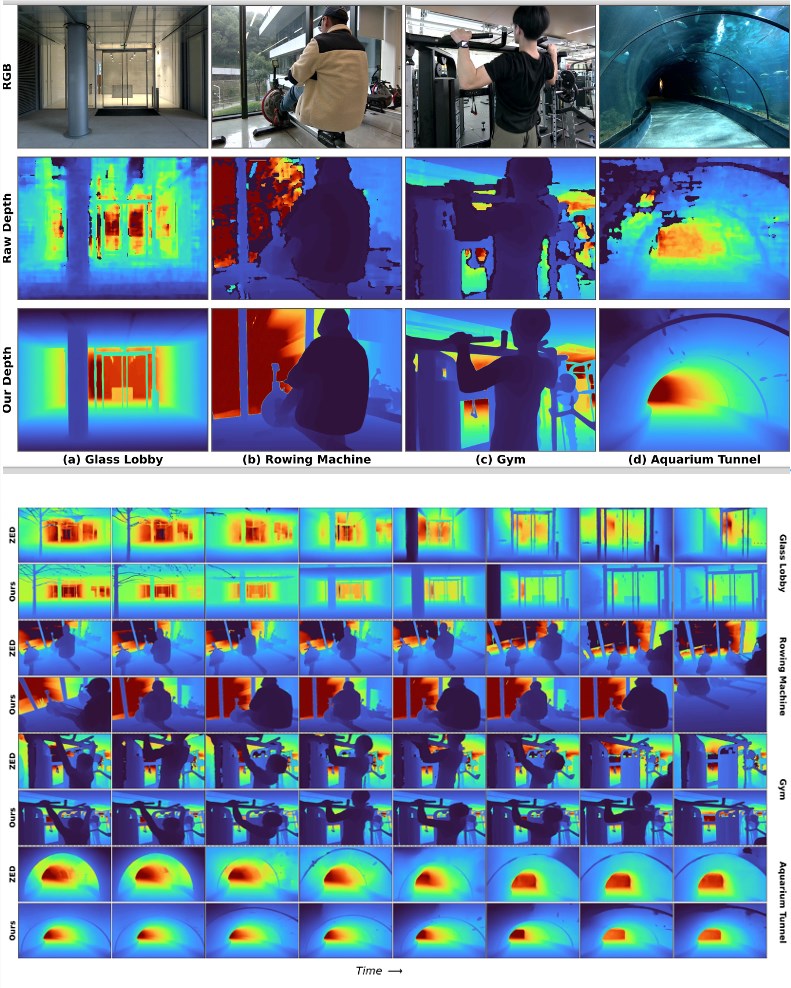
- 支持超万帧长视频的持续三维重建
- 处理速度约为20 FPS,满足多数机器人和智能终端的实时需求
- 在恒定内存约束下实现长时间建模,避免系统资源耗尽
该模型并非依赖高端激光雷达或多光谱传感器,而是通过自回归机制和视频流分析,从常规RGB视频中提取空间结构信息,从而实现对物理环境的高保真建模。这种能力使得LingBot-Map成为当前流式三维重建领域中,少有的可以运行在普通计算平台上的解决方案。
与其他模型的对比与优势
LingBot-Map并非孤立的技术点,而是蚂蚁灵波通用世界模型生态中的关键一环。相比于特斯拉Optimus、Genie3等主流世界模型,LingBot-Map有以下几项显著特点:
- 开源与低门槛:LingBot系列模型全部开源,允许开发者快速部署和迭代,降低了研究与应用成本
- 闭环交互机制:在运行过程中不断与真实环境交互,修正预测偏差,提升长期任务的稳定性
- 统一的潜空间映射:通过MoT(Mix-of-Transformer)架构,将视频与动作序列映射至统一空间,实现动作与环境的精准对齐
- 稀疏化与去噪策略:根据视频和动作流的特性差异进行分层处理,提高模型效率和控制精度
在LIBERO和RoboTwin等基准测试中,LingBot-Map展现出超过92%的任务成功率,尤其在复杂、长期任务中表现出色,有效缓解了传统VLA模型中的“长时漂移”问题。
行业影响与未来展望
LingBot-Map的发布为机器人视觉感知与三维重建提供了新的技术路径。它不仅支持低成本摄像头的实时重建,还为智能体的模拟训练、动作规划与闭环控制提供了统一的模型接口。对于开发者而言,这意味着更便捷的部署流程和更强的二次开发潜力。
未来,随着LingBot-VA等模型与LingBot-Map的进一步融合,机器人将能够实现从“观察”到“推理”再到“行动”的完整闭环。这种统一世界模型的构建方式,有望在家庭服务机器人、工业自动化和自动驾驶等多个场景中发挥重要作用。
蚂蚁灵波在短短数日内连续发布多个核心模型,展现出其在具身智能领域的系统性布局。LingBot-Map的开源,标志着三维感知技术正从专用硬件走向大众化应用,为通用人工智能的发展提供了更坚实的基础。