每秒每 GPU 处理 8064 个词元:英伟达刷新 DeepSeek-R1 推理速度纪录

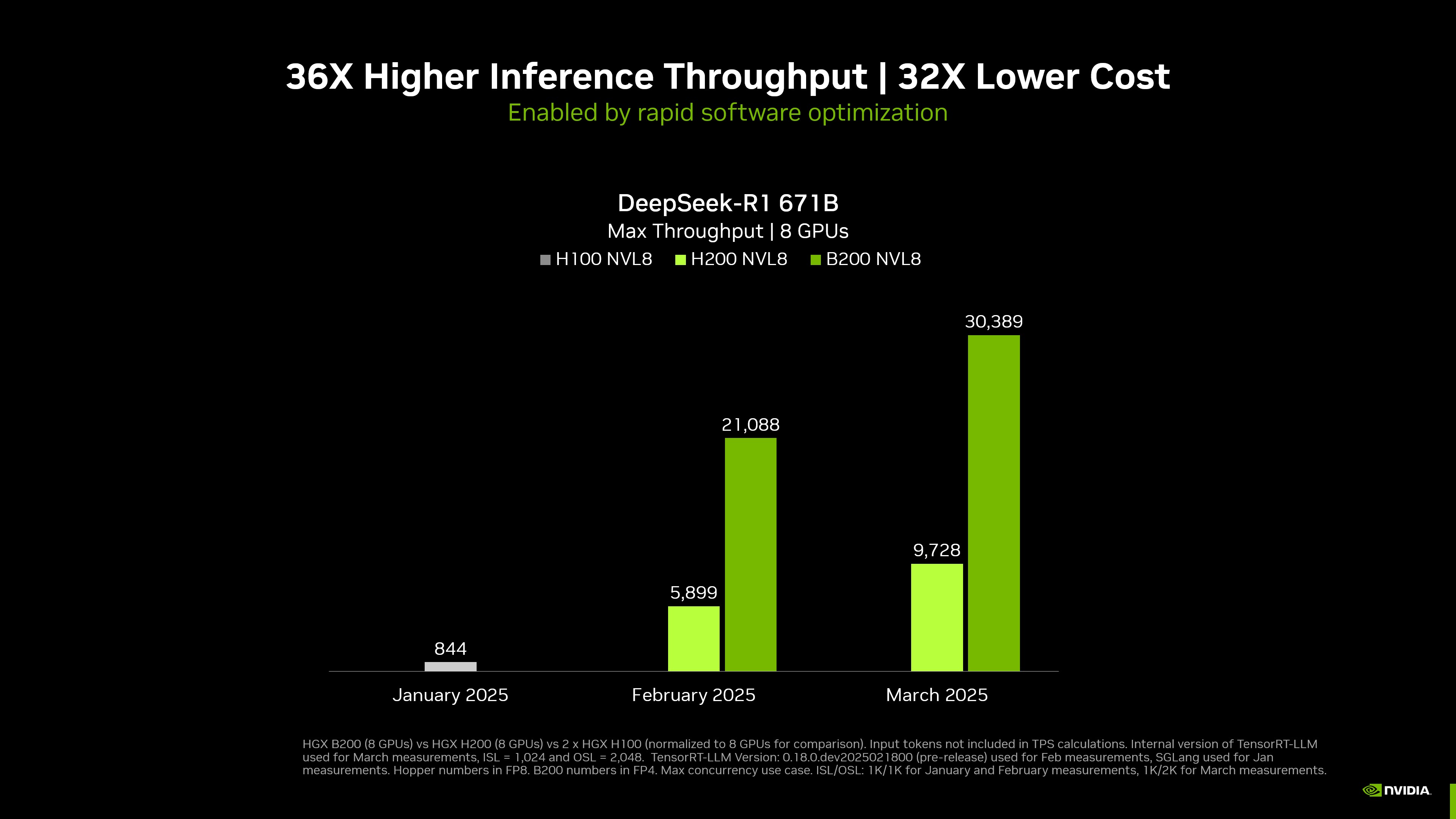
英伟达的DGX系统搭载最新的Blackwell GPU,在运行开源模型DeepSeek-R1时,实现了前所未有的推理性能,单节点八块B200 GPU达到了每秒超过30,000个token的峰值吞吐量,同时每个GPU处理速度高达8064个token/s。
背景:开源模型与硬件优化的协同趋势
近年来,大语言模型(LLM)的推理效率成为关键瓶颈,尤其是在部署高并发任务时。DeepSeek-R1作为一款采用多头潜在注意力机制(MLA)和大型稀疏混合专家模型(MoE)架构的开源模型,具有极高的潜力,但其性能的释放依赖于软硬件协同优化。
英伟达持续推动AI推理效率的边界,其最新的Blackwell架构GPU提供了更强的计算能力和更高的能效。在此基础上,结合TensorRT-LLM的深度优化,使得在运行DeepSeek-R1这样的复杂模型时,推理性能有了突破性提升。
优化细节:FP4量化与KV缓存管理
为了提升推理效率,英伟达对DeepSeek-R1进行了深度量化优化。原始的FP8 Checkpoint大小约为640GB,而经过NVIDIA模型优化器处理的FP4量化版本大小缩小至约400GB,显著减少了模型权重的显存占用。
这一优化带来了以下优势:
- 每个GPU的权重和激活占用显存约为80GB。
- 每个GPU拥有100GB可用KV缓存。
- 假设输入序列长度(ISL)为1K,输出序列长度(OSL)为2K,每次请求消耗约200MB KV缓存。
- 单个GPU可支持高达500的并发数,8 GPU系统的全局并发数可达4000。
使用ATP(Active Token Parallelism)时,虽然全局并发性下降至500,但端到端生成效率得到进一步提升。
性能提升:从基线版本到Blackwell优化成果
经过TensorRT-LLM框架内的多项优化,端到端推理速度相比2月份的基线版本提升了20%。英伟达通过以下关键措施实现了这一飞跃:
- 高吞吐量生成MLA内核:使用Blackwell GPU的Tensor Core第五代MMA指令,实现了2CTA组变体的高效执行。
- 计算重叠优化:采用interleaved tile技术,将MLA计算与softmax操作进行重叠执行,提高计算资源利用率。
- 问题规模自适应内核选择:针对DeepSeek-R1的结构特点,微调内核选择的启发式算法,使其更适配特定的推理任务。
通过这些优化手段,TensorRT-LLM在每个GPU上的吞吐量(TPS/GPU)提升了近2.3倍,最终实现了每GPU高达8064个token/s的处理能力。
影响:推动LLM推理部署效率迈上新台阶
英伟达此次的优化成果,标志着在开源大语言模型部署方面迈出了关键一步。开发者可以在Blackwell架构的GPU上更高效地运行DeepSeek-R1,尤其是在需要高吞吐量的场景,例如:
- 面向大规模用户的自然语言处理服务
- 高并发文本生成任务
- 混合专家模型的动态路由优化
- 实时AI客服、自动摘要、多语言翻译等应用
此次优化不仅提升了单节点性能,也展示了NVIDIA在构建端到端AI推理生态上的持续投入,包括TensorRT-LLM、CUDA工具链以及Blackwell架构硬件的协同进步。
展望:开源模型与TensorRT-LLM的未来协同
英伟达工程团队表示,未来将继续深入研究MLA、MoE等新型模型结构的运行时优化策略,并进一步完善TensorRT-LLM以支持更多模型和硬件组合。这一成果也为广大AI开发者提供了可参考的优化思路,特别是在处理显存瓶颈、调度并行任务和设计高效推理内核方面。
英伟达强调,开发者可以通过nvidia/DeepSeek-R1-FP4仓库获取优化后的模型Checkpoint,并在Blackwell GPU上复现该高性能推理方案,推动AI应用向更高效率、更低延迟迈进。