美团发布开源原生多模态大模型 LongCat-Next,让视觉和语音成为 AI 的母语

LongCat-Next 是美团大模型团队发布的一款原生多模态大模型,旨在打破传统AI模型以“语言为中心”的局限。该模型的核心理念是通过纯粹的“下一个Token预测”范式,让视觉与语音成为AI的“原生母语”,而非需要复杂拼凑的“第二语言”。
核心技术突破:离散原生自回归架构
LongCat-Next 最显著的创新在于其底层架构的重构。传统多模态模型往往采用分开处理不同模态再进行融合的“拼凑式”架构,而 LongCat-Next 采用 离散原生自回归架构(DiNA),实现了真正的统一处理。
- 统一词元空间:该架构将语言、视觉和音频三大模态的信息全部统一内化到共享的离散词元空间中进行建模。这意味着无论是文本、图像还是语音,都被视为同源的离散Token。
- 单一预测范式:通过“下一词元预测”机制,模型能够像生成文本一样生成图像和语音,彻底打破了模态之间的隔阂。
- 任意分辨率视觉处理:团队还提出了 离散原生任意分辨率视觉 Transformer(dNaViT),它能将图像编码为具有语义完整性的离散ID,支持任意分辨率的理解与生成,有效调和了视觉理解与生成任务之间的冲突。
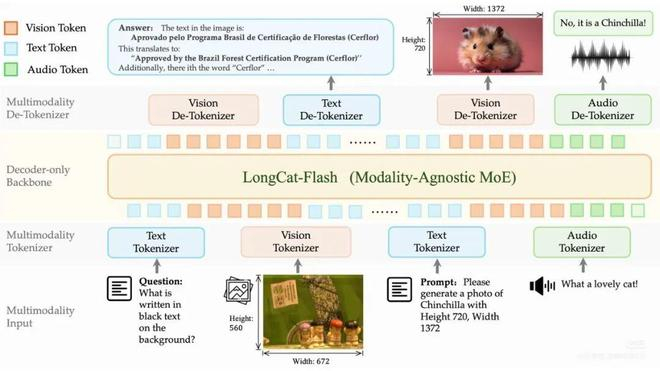
模型性能与参数规模
LongCat-Next 在保证强大能力的同时,也兼顾了工业级的部署效率。
- 参数配置:模型总计拥有 685亿参数,但在推理时仅激活 30亿参数。
- 架构基础:基于此前发布的 LongCat-Flash-Lite 混合专家(MoE)架构构建,这使得模型在性能与能耗之间取得了优异的平衡。
- 能力表现:
- 视觉理解:覆盖OCR、图表解析、GUI界面解释、文档分析及高级STEM推理。
- 视觉生成:在28倍压缩比下实现任意分辨率的图像生成,且在文本渲染质量上表现突出。
- 语音交互:具备强大的音频理解能力,支持低延迟智能语音交互及可定制的语音克隆合成。
生态布局与开源开放
作为美团 LongCat 系列模型生态的重要一员,LongCat-Next 的发布进一步完善了美团的开源多模态版图。此前,该团队已开源了涵盖文本、图像、视频及全模态交互的一系列模型。
为了促进AI技术的共享与创新,美团团队已全面开放了 LongCat-Next 的资源:
- 技术报告:详细阐述模型原理与实验数据。
- 模型权重与代码:托管在 GitHub 和 HuggingFace,供开发者下载与部署。
- 在线演示:用户可在 longcat.chat/longcat-next 体验模型能力。
LongCat-Next 的出现,标志着美团在通往物理世界AI的道路上迈出了关键一步,通过将视觉与语音原生纳入语言建模逻辑,构建了一种更具泛化能力的智能形式。