美团LongCat-Next:把图像、声音、文字都变成Token,然后呢?

背景:LLM与多模态模型的割裂
传统大语言模型(LLM)依赖于文本的离散Token进行训练和推理,而多模态模型则通常采用“拼接式”架构,即图像、语音等模态先由独立模块处理,再将结果输入语言模型进行融合。这种架构存在明显的“信息损耗”与“建模割裂”问题,导致模型对多模态输入的理解不够自然和深入。美团提出LongCat-Next的目标,是打破这种割裂,将图像、语音等信号统一转化为离散Token,从而实现真正的“原生多模态”处理。
传统多模态模型的问题
- 多模态处理依赖外部编码器,如CNN、ViT等,生成的特征向量为连续表示
- 语言模型处理离散序列,连续向量需要额外适配,难以形成统一认知
- 图像、语音等模态无法直接参与自回归生成,限制了跨模态互动的可能性
技术方案:DiNA架构与视觉“分词-解词”
LongCat-Next的核心在于DiNA(Discrete Native Autoregressive)架构,该架构将语言、图像、语音统一为“离散Token序列”,并以“自回归预测下一个Token”的方式统一建模。这不仅仅是模型能力的扩展,更是对多模态建模范式的根本性尝试。
DiNA架构的关键组成
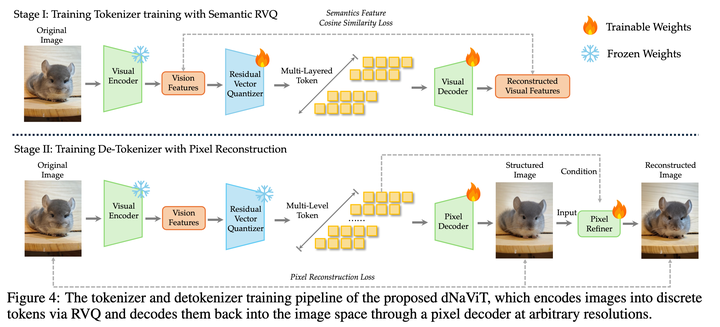
- SAE(Semantic-Aware Encoder):先对图像进行语义感知编码,确保生成的Token具备语义表达能力,而非仅用于压缩
- dNaViT(discrete Native Vision Transformer):将视觉表示转化为离散Token序列,保留图像结构、分辨率和长宽比,适用于OCR、文档分析等任务
- RVQ(Residual Vector Quantization):分层量化视觉信息,先提取大结构,再逐层补充细节,避免语义与结构信息在压缩过程中互相干扰
模型能力:统一的Token世界
在LongCat-Next中,无论输入是文本、图像还是语音,模型都将其视为离散Token序列进行处理。这意味着,模型能够进行跨模态的自回归预测:
- 给定文本Token,预测后续文本Token(语言建模)
- 给定图像Token,预测文本Token(视觉理解)
- 给定文本Token,预测图像Token(图像生成)
- 给定语音Token,预测文本或语音Token(语音理解和语音对话)
这种方式不仅让模型在多模态任务中表现更一致,还让图像、语音的“生成”与“理解”共享一套建模逻辑,从而提升整体泛化能力。
实现目标:视觉版的“分词-解词”
LongCat-Next试图实现图像处理中的“分词-解词”机制,就像语言模型对文本进行切词、建模、再组合一样。图像进入模型后,首先被拆解为具有语义和结构信息的离散Token,再通过统一的语言模型进行理解或重建。
视觉分词的挑战
- 既要保留语义(如文字、物体识别),又要保留结构(如版式、分辨率)
- 传统视觉Token化方法(如VAE)容易丢失细节,导致理解受限
- 必须在“压缩”与“表达”之间取得平衡,不能仅作为图像编码器
LongCat-Next通过dNaViT和RVQ的组合,解决了这一问题。图像既能被“看懂”,也能被“画回去”,形成闭环的视觉语言建模。
意义与影响:重新定义多模态建模
LongCat-Next的核心价值在于它不是在给语言模型“”视觉或语音模块,而是从底层将图像、语音等模态“内化”为语言模型世界观中的一部分。这标志着多模态建模正从“拼接”走向“统一”。
长远影响可能包括:
- 建模范式变革:不再需要为不同模态设计独立的架构,统一使用NTP(Next Token Prediction)建模
- 跨模态理解更自然:模型可直接从图像Token预测语音Token,实现更深层次的跨模态推理
- 生成与理解一体化:Token的双向流动使得图像、语音等模态的生成与理解基于同一逻辑,提升可控性与一致性
- 推动多模态SOTA:已在多个多模态Benchmark中达到领先水平,甚至取得SOTA(State of the Art)表现
如果过去LLM的成功在于“预测下一个字”的范式,那LongCat-Next则试图证明:这套范式不只适用于语言,也可能适用于整个感知世界。