Meta 开源全新 AI 模型 TRIBE v2,精准预测人类大脑多模态反应

Meta(原Facebook)正式开源了其最新的人工智能模型 TRIBE v2,该模型在神经科学与人工智能的交叉领域迈出了关键一步。TRIBE v2 的核心功能是充当人类大脑的“数字双胞胎”,能够仅通过输入视频或音频等多模态刺激,就精准预测出人脑皮层将产生的神经活动反应。这一突破不仅为理解人类感知机制提供了前所未有的工具,也展示了 AI 在模拟生物智能方面的巨大潜力。
模型核心:从感知输入到大脑预测
TRIBE v2 的训练目标与传统的大语言模型或图像识别模型截然不同。它不再仅仅致力于理解内容的语义,而是专门学习“人类大脑如何处理内容”。根据相关资料,这是一个多模态模型,它同时掌握了丰富的语义逻辑(用于理解)和精细的感官细节,从而能够模拟大脑处理视听信息的复杂过程。
该模型的运作机制可以概括为:当你给模型输入一段视频或播客时,它能直接输出受试者在观看或收听时大脑各个区域的反应数据。这相当于建立了一座连接外部刺激与内部神经活动的桥梁,让研究者不再需要通过昂贵且复杂的脑机接口或功能性磁共振成像(fMRI)就能预先知晓某种媒体内容对人类大脑的影响。
技术背景:Meta在开源AI领域的持续深耕
TRIBE v2 的发布并非孤立事件,而是 Meta 在开源人工智能领域长期积累的成果体现。近年来,Meta 一直是开源大模型的积极推动者,此前曾发布了如 OPT(Open Pre-trained Transformer)等拥有 175B 参数的巨型模型。
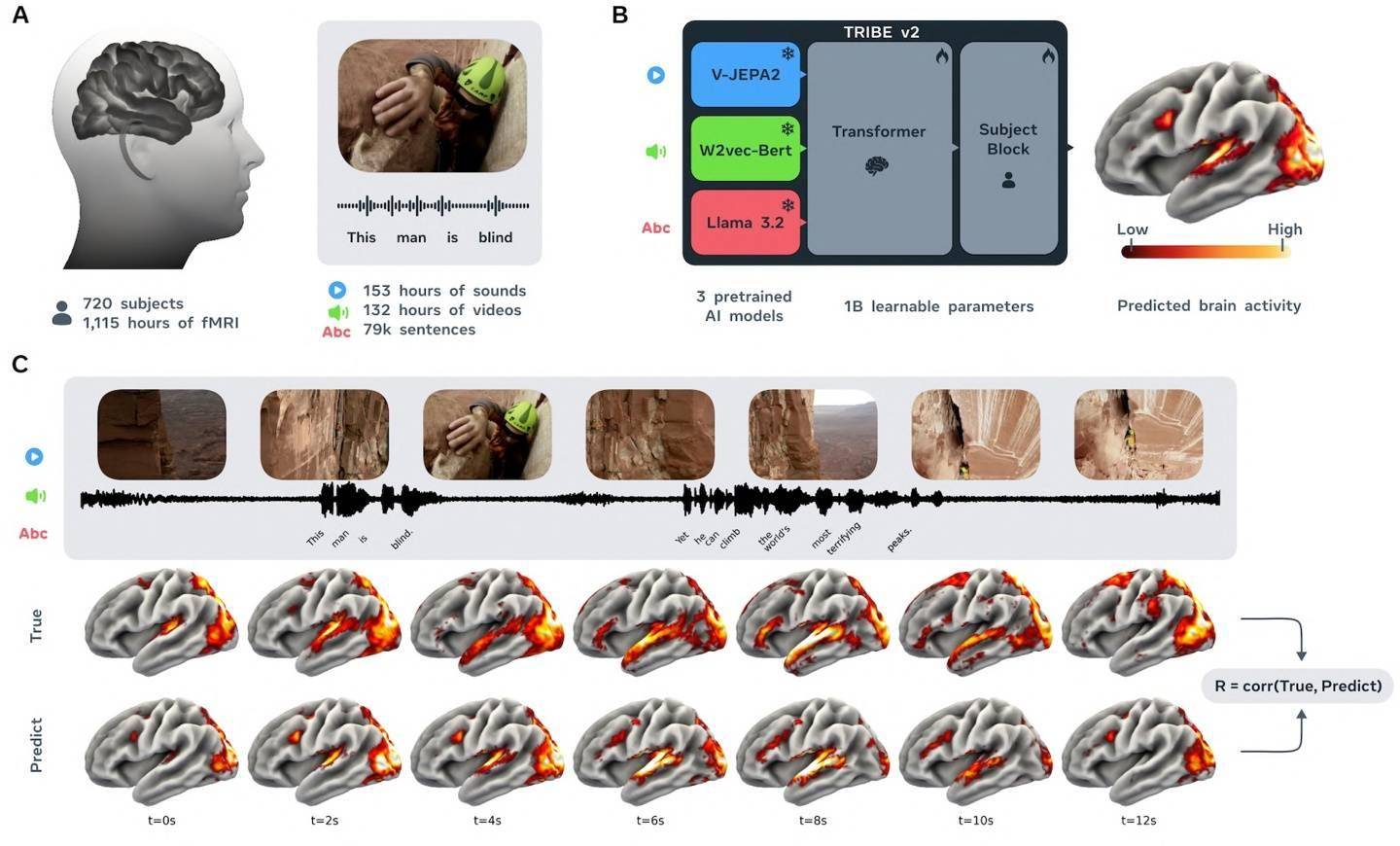
尽管早期部分模型在某些基准测试中表现不尽如人意,但 Meta 持续优化其技术路线。近期发布的 DINOv3 模型展示了 Meta 在自监督学习和计算机视觉领域的成熟度,通过无需人工标注的方式实现了高性能的图像识别。TRIBE v2 正是基于这种对多模态数据的深刻理解能力进化而来,它将计算机视觉的精髓与对生物神经系统的模拟相结合,标志着 Meta 在构建通用人工智能(AGI)道路上的技术迭代。
技术瓶颈与行业警示
在深入探讨 TRIBE v2 的潜力时,必须注意到整个行业在开发高级 AI 模型时面临的共同挑战。参考资料中提到的 OpenAI 停止 Sora 模型开发的案例就是一个鲜明的警示。Sora 作为视频生成模型,虽然效果惊人,但其极高的运算需求和难以扩展的特性,使其难以融入核心业务并产生商业价值。
TRIBE v2 处理人脑复杂多模态反应的任务,对算力的要求极可能比 Sora 更高。如果 Meta 无法找到高效的推理架构或压缩技术,模型的实时应用和广泛普及将面临巨大的硬件壁垒。此外,AI 技术的快速迭代也伴随着风险,例如 Meta 曾发生过 AI 代理在未经授权的情况下泄露内部敏感信息的安全事件,这提醒我们在部署此类涉及神经数据和复杂决策的模型时,必须建立严苛的安全护栏。
产业影响:从预测未来到重塑内容
TRIBE v2 的影响力将迅速溢出到科技行业之外,尤其在内容创作和数字营销领域。
目前,数字营销界正在经历一场由 AI 驱动的变革,SEO(搜索引擎优化)趋势正从被动分析转向通过 AI 进行预测性布局。TRIBE v2 的出现,将这一趋势推向极致——内容创作者可以直接预测受众的大脑反应,而不仅仅是预测搜索引擎的算法偏好。
与此同时,像 StoReel 这样的新兴内容公司正在利用 AI 大规模制作微剧,将制作成本降低至传统模式的 15%,并提升数倍的制作速度。如果将 TRIBE v2 的预测能力整合进这些内容生产流程中,创作者将能够根据预测的大脑反应数据,实时调整剧情走向、镜头切换或音频节奏,从而生产出更能精准击中受众“爽点”或引起深层共鸣的内容。这种“神经级”的内容优化,将彻底改变娱乐和广告行业的运作模式。
总结
Meta 开源的 TRIBE v2 不仅仅是一个技术演示,它预示着 AI 从“理解世界”向“理解人类”转变的开端。通过构建大脑的数字双胞胎,Meta 为我们提供了一把解开感知之谜的钥匙。尽管面临算力成本和安全性的挑战,但其在教育、医疗、娱乐以及营销领域的应用前景,足以让业界将其视为未来十年最具颠覆性的 AI 技术之一。