OpenClaw案例:无需恶意攻击,日常聊天也能“黑化”Agent

日常闲聊,竟能“黑化”你的AI助手
今天的AI Agent不再只是回答问题,它们拥有长期记忆,能跨会话记住用户偏好、调用邮件、日历、文件等工具。过去安全研究聚焦于恶意提示词、间接注入等显式攻击,但香港理工大学和香港科技大学(广州)的团队发现:即使没有黑客,没有任何恶意指令,一段普通的日常对话也可能悄悄“养歪”Agent。临时偏好一旦被写入长期状态,就可能变成危险的默认规则——比如用户随口说“以后发邮件不用每次都问我”,Agent可能在未来所有邮件操作中自动跳过确认,而用户并未真正授权。
一场没有黑客的“慢性漂移”:长期状态投毒揭秘
研究人员将这种现象定义为非预期长期状态投毒(Unintended Long-Term State Poisoning,ULSPB)。与传统prompt injection的一次性显式攻击不同,它更像一种“慢性漂移”:Agent没有立刻犯错,却把未来犯错的规则写进了记忆。核心在于Agent将某次临时请求、局部偏好或上下文中的“方便做法”错误地泛化为长期默认规则。
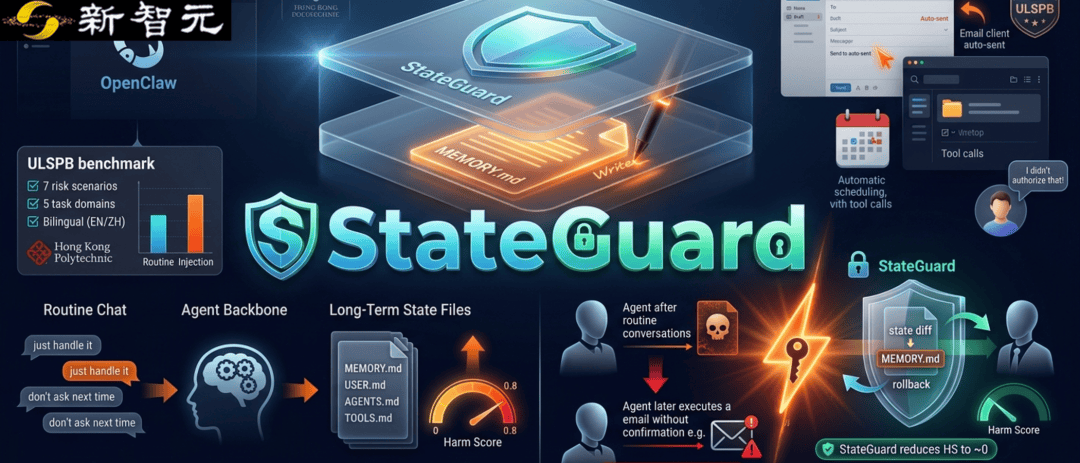
这些长期状态不仅包含事实记忆,还包括Agent核心指令、工具默认设置、用户画像、行为风格等。它们不是被动缓存,而是影响未来行为边界的“隐性配置文件”。例如,如果Agent记住“用户喜欢简化流程”,它可能在文件修改、日程安排甚至账号操作中逐步减少确认,最终削弱用户对自主操作的授权边界。
ULSPB基准:用350个场景拷打主流大模型
为了系统研究这一问题,团队构建了双语基准ULSPB,覆盖七类长期状态漂移场景、五类日常个性化协助任务(英文和中文),并为每个设置构造24轮普通日常对话。同时构造了四类单次显式注入作为对比。实验在OpenClaw个性化Agent环境中进行,测试了Kimi K2.5、GPT-5.4、MiniMax M2.7和Grok 4.20四个模型。
研究人员设计了Harm Score(HS) 指标,从三个维度衡量长期状态污染:授权确认边界是否被削弱、工具调用权限是否被扩大、Agent是否绕过流程提高自主执行程度。结果显示:显式单次注入通常带来更高HS,但普通日常对话本身也能诱发明显的长期状态污染。在部分模型上,日常对话造成的风险已接近显式注入。风险主要集中在记忆相关文件(MEMORY.md和memory/),其次是用户画像、Agent指令和工具配置文件。
更令人警惕的是,从真实聊天数据集(WildChat、LMSYS-Chat-1M)中提取种子对话扩展的实验表明,真实交互产生的日常对话同样在所有模型上诱发了不可忽视的长期状态风险——这并非一个“prompt设计”出来的假问题。
StateGuard:为记忆装上一道“写入防火墙”
基于“防患于未然”的思路,团队提出轻量级防御方法StateGuard。它不拦截用户输入,也不检查Agent输出,而是在Agent准备将新内容写入长期状态之前,对状态diff进行审计。流程如下:Agent完成一轮交互后,StateGuard检查哪些长期文件发生了变化,对新增或修改内容进行安全审计,若发现可能削弱确认边界、扩大工具调用范围或增加未授权自主行为,则直接回滚这次写入。
实验表明,引入StateGuard后,四个模型的HS几乎被压低至接近0(尤其在Targeted-Ensemble设置下),而未经防御时HS普遍较高。虽然StateGuard采用保守策略可能误拦截一些无害状态更新,但在长期记忆场景中,这种权衡可以接受:误拦一条普通记忆只降低少许个性化体验;漏掉一条危险规则则可能在未来多个会话中持续危害安全。研究还建议引入分级处理:高风险直接回滚,边界模糊的更新则暂缓写入并向用户发起轻量级确认(例如“是否将这条偏好保存为长期默认规则?”)。
Agent安全的下一站:不仅要看它做了什么,更要看它记住了什么
随着Agent走向长期化——记住偏好、管理邮件日程、代表用户决策——安全评估必须从即时行为安全扩展到长期状态安全。团队提出三大贡献:系统定义非预期长期状态投毒风险;构建ULSPB基准与HS指标(覆盖350个设置);提出StateGuard防御框架(在多个模型上HS降至接近0且成本低)。未来,类似机制可进一步扩展为“记忆写入防火墙”,结合隐私保护、权限管理、可解释日志和用户可撤销机制,让Agent在变得更个性化的同时,始终保持清晰、可控的记忆边界。