苹果联合打造 RubiCap 框架:让 AI 描述图像每个细节,性能击败 10 倍体量对手

在AI图像描述领域,传统方法长期面临着一个根本性的教学困境。现有的技术要么强迫模型死记硬背固定的描述模板,导致模型缺乏对新颖场景的适应能力;要么依赖粗糙的通用评分标准,如同用一把钝尺去测量精密零件,无法捕捉描述质量的细微差别。这种局限性不仅限制了AI描述的准确性和丰富性,还容易引发“灾难性遗忘”现象——即模型在过度优化描述能力时,丧失了原有的视觉理解技能。
RubiCap的革命性创新在于引入了一套动态的、针对每张图片量身定制的“智能评分系统”。这套系统的工作流程极富巧思,首先,它召集一个由多款顶尖AI组成的“专家委员会”,包括Gemini 2.5 Pro、GPT-5等模型,让它们对同一张图片进行独立描述。系统隐藏了各专家的身份,通过“民主投票”机制,仅保留至少半数以上专家都提及的细节作为该图片的“标准答案”。这一过程有效过滤了单个模型的幻觉或错误,确立了可靠的基准。
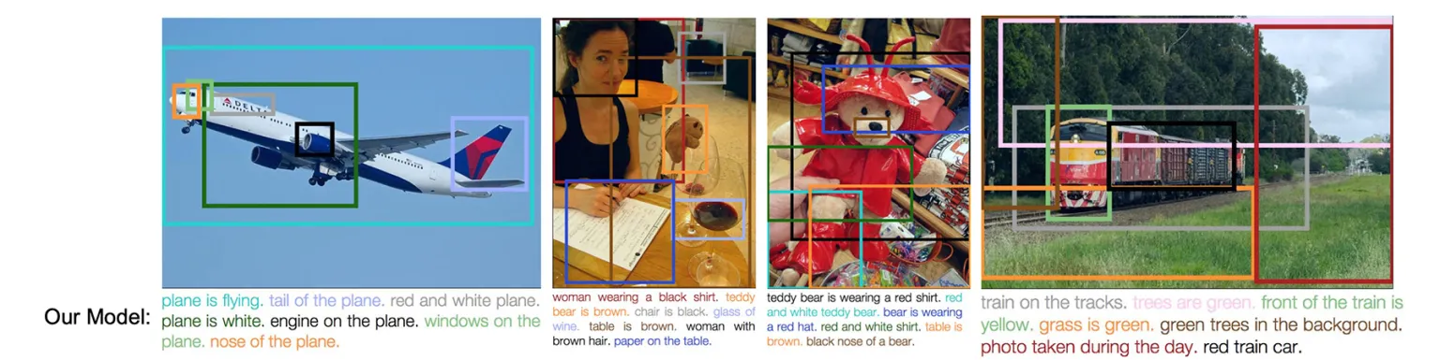
基于这个基准,RubiCap的“评分标准制定器”扮演了智能诊断医生的角色。它会将待训练模型(学生)的描述与专家共识进行深度语义对比,精准找出遗漏、错误或模糊之处。随后,系统会生成一套个性化的评判细则,例如“是否准确识别了蛋糕上的‘24 CARROT CAKE’字样”或“是否描述了背景中的树木”。这些细则不仅是二元的对错判断,还根据重要性赋予权重,指导模型区分主次。
在训练阶段,RubiCap利用这些细化的标准进行精密的强化学习。模型针对同一张图片生成多个描述版本,由专门的评判官根据评分细则打分。通过“群组相对策略优化”算法,模型学会比较不同表述的优劣,从而在保持创造性的同时提升准确性。这种“教会AI如何学习”而非“灌输标准答案”的方式,从根本上解决了传统方法的弊端。
实验结果充分验证了RubiCap的威力。在CapArena等基准测试中,RubiCap 7B模型在盲评中击败了规模大得多的72B和32B前沿模型,获得了最高胜率。同时,该模型在词汇效率上表现惊人,RubiCap 3B模型甚至超过了7B基础模型,显示出“巧胜于大”的优势。更重要的是,经过RubiCap训练的模型在10个不同的视觉理解基准测试中均保持了高水准,有效避免了“灾难性遗忘”,展现了更强的综合能力。
这项技术的潜在影响深远。在实际应用中,该模型在100词限制下的信息密度提升了12.01%,非常适合用于大规模数据标注,能够以低成本的开源模型替代昂贵的商业服务。从医疗影像分析、自动驾驶环境感知到为视障人士提供辅助服务,RubiCap所代表的精细化视觉理解技术都有广阔的应用前景。它标志着AI发展思路的一个重要转折:从盲目追求模型参数的规模竞赛,回归到对训练机制与学习效率的根本性创新。