全球顶尖大模型一夜惨遭血洗,最难测试人类拿满分,AI第一名得0.2%分

ARC-AGI-3基准测试的推出,标志着对人工智能通用智能(AGI)评估的一次范式转变,它将AI从处理静态数据推向了与动态、未知环境互动的挑战。这项测试迅速成为检验模型真实智能水平的“试金石”,因为它摒弃了传统的题海战术,转向了对即时学习和适应能力的纯粹考验。当结果揭晓时,整个AI社区为之震动:被誉为业界标杆的顶尖模型,包括在前代测试中表现优异的Opus 4.6,在全新的高难度面前几乎“全军覆没”。
颠覆性的测试设计
ARC-AGI-3彻底改变了游戏规则。它不再是让AI回答书面问题,而是将其抛入一个又一个独立的“互动游戏”中。这些游戏没有提供任何说明书或自然语言提示,其内在逻辑、规则和通关条件完全是隐藏的。AI智能体必须像一个初次接触新游戏的玩家一样,通过观察屏幕画面、尝试操作、理解反馈结果,逐步在内部构建出对虚拟世界运作方式的认知模型。这种设计直接命中了当前AI的软肋:从被动的知识存储转向主动的环境洞察与推理。
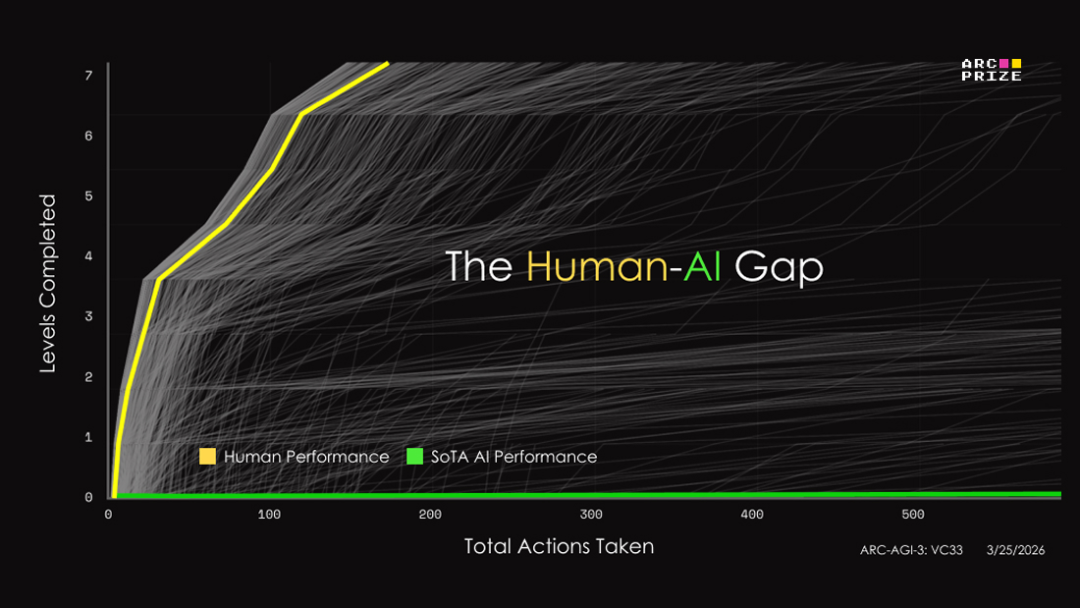
残酷的评分法则
评分机制的设计极具深意且极其严苛。它不只关心AI是否能通关,更关键的是衡量其解决问题的“效率”,并与人类表现进行直接对比。具体的计算公式引用自AI先驱François Chollet的理论:(人类步数 / AI步数)²。例如,如果某个人类玩家用了10步完成任务,而AI花费了224步,那么AI在该任务上的得分仅为0.2%。这种几何级数的计分方式,对低效的蛮力尝试给予了近乎毁灭性的惩罚。结果是,曾经在基准测试中叱咤风云的ClaudeOpus 4.6,在这项测试中仅取得了0.2%的惨淡分数,与其前身在旧测试中69.2%的成绩形成鲜明对比。
刷榜模型为何失效?
令人意外的是,在排行榜上名列前茅的并非那些我们熟知的超大规模语言模型,而是基于卷积神经网络(CNN)的强化学习智能体和基于规则的图搜索系统。这些非LLM方案反而取得了高于10%的成绩,远超GPT-5.x等先进模型。这揭示了一个反直觉的现象:参数量更大、知识库更丰富的模型,在此次测试中表现反而更差,甚至时常崩溃。原因在于,面对一个完全陌生的环境,这些大模型倾向于依赖其庞大的先验知识进行过度的“脑补”,将新环境错误地映射到自己熟悉的模式中,一旦假设错误,便会沿着错误方向一去不复返。
人类与AI的根本差异
ARC-AGI-3清晰地展示了人类智能与当前AI之间的鸿沟。人类在面对新任务时,本能地执行着“观察-构建模型-验证-修正”的循环,我们能够快速建立一个虽然粗糙但有效的世界模型,并随时准备推翻它。这是一种基于假设驱动的在线学习。相反,目前的AI更像是一个知识渊博的“应试专家”,其核心能力是基于海量数据的离线模式匹配。它在已知领域表现出色,但在需要从零开始、真正“学习如何学习”的未知领域则显得力不从心。ARC团队一针见血地指出,真正的智能在于“构建思维模型”的能力,而这恰恰是当前AI与人类最大的差距所在。