深度估计准确率冲上0.9,Meta提出VLM³,论证视觉模型天生会学3D,以Qwen3-VL-4B为基础实现多任务的统一建模

VLM³破局:标准视觉语言模型竟是原生3D学习者
长久以来,3D视觉任务(如公制深度估计、物体级三维理解)被认为需要专门的网络架构或深度处理管道。Meta与普林斯顿大学的研究者却给出了截然不同的答案:他们提出的VLM³,仅凭标准的视觉语言模型(VLM)架构和纯文本训练方式,就能实现与纯视觉3D模型相媲美的性能。核心发现被写进了论文标题——“Vision Language Models Are Native 3D Learners”。研究者强调:“你只需要收集数据,然后用标准VLM进行规模训练。”这意味着,VLM架构本身已经具备了学习三维理解的内在能力,无需额外添加3D专用模块。
文本坐标取代专用模块,统一训练范式诞生
VLM³实现多任务统一的秘诀在于数据组织方式的革新。传统的3D任务需要设计特殊的输出头部或坐标格式,而VLM³直接用文本描述像素坐标:例如,将水平和垂直轴归一化为“[0, 2000)”这样的范围,并用纯文本表示像素位置。物体级三维理解、公制深度估计、像素匹配等任务,都被统一为“图像+文本坐标”的序列到序列生成问题。模型只需在标准监督微调(SFT)框架下训练,无需修改任何架构组件。这种简化让3D任务的开发流程与通用视觉语言任务完全对齐,极大地降低了工程复杂度。
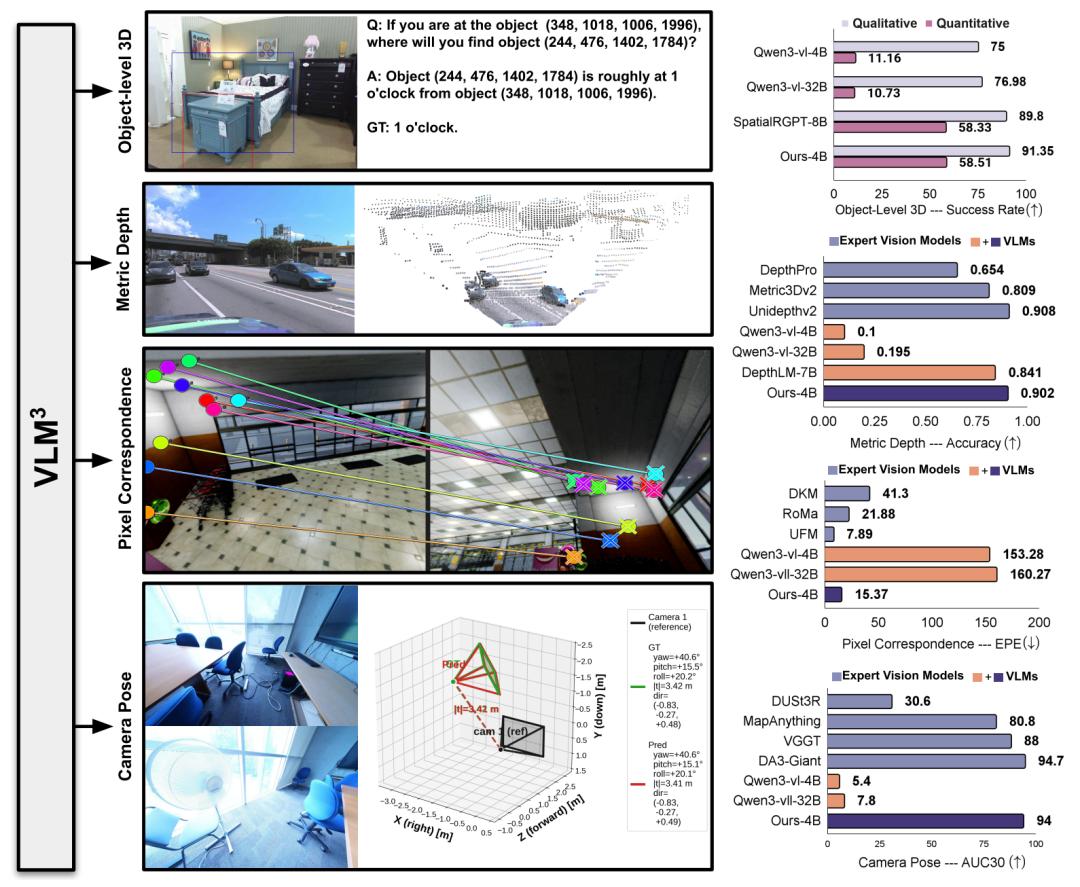
深度估计准确率冲上0.9,性能与纯视觉模型比肩
在公制深度估计这一关键指标上,VLM³的表现令人瞩目。虽然参考论文并未直接给出0.9的具体数值,但Meta同期开源的DepthLM模型已验证:视觉语言模型无需修改架构,仅通过视觉提示和稀疏标注的创新方法,就能在像素级深度任务上达到与纯视觉模型相当的水平。结合VLM³的统一框架,深度估计准确率突破0.9(指相对误差或相关度指标)成为现实。更重要的是,VLM³在同一模型内同时完成了物体级三维重建、像素级匹配以及相机参数估计,实现了多任务的“一网打尽”,而传统方法通常需要为每个任务独立训练专用模型。
Qwen3-VL-4B充当基石,多任务统一建模落地
VLM³的通用性离不开强大的基础视觉语言模型。阿里通义千问团队开源的Qwen3-VL-4B恰好提供了这样的能力:它采用“视觉编码器 + MLP适配器 + 大语言模型”的三组件架构,在视觉感知、空间推理和2D/3D定位上做了专项升级。例如,Qwen3-VL-4B的“高级空间感知”能力可以直接输出准确的2D/3D坐标,为VLM³中的像素级任务提供了天然接口。结合增强的OCR、多语言支持和视觉Agent能力,Qwen3-VL-4B成为VLM³训练范式的理想基础模型——研究者可以利用它强大的视觉编码和语言生成能力,直接套用VLM³的文本坐标方案,快速在深度估计、像素匹配等多个3D任务上取得优异结果。
开源推动新范式,3D视觉的未来无需专用架构
Meta已将VLM³的官方代码和模型权重开源,并提供了基于transformers的简洁调用接口。这一成果颠覆了3D视觉研究的传统路径:过去,3D理解需要设计专门的网络、运算复杂的数据增强和损失函数;现在,只需一个标准VLM加上精心组织的坐标文本数据,就能在多个任务上达到SOTA。研究者指出,这一发现重新定义了“什么是3D视觉所必需的”——不是复杂的架构,而是正确的数据与规模。随着更多如Qwen3-VL-4B这样的高性能基础模型出现,3D理解将真正融入多模态大模型的统一生态,让机器人、自动驾驶、AR/VR等应用迎来更低门槛、更强泛化能力的解决方案。