当前标签:视觉语言模型
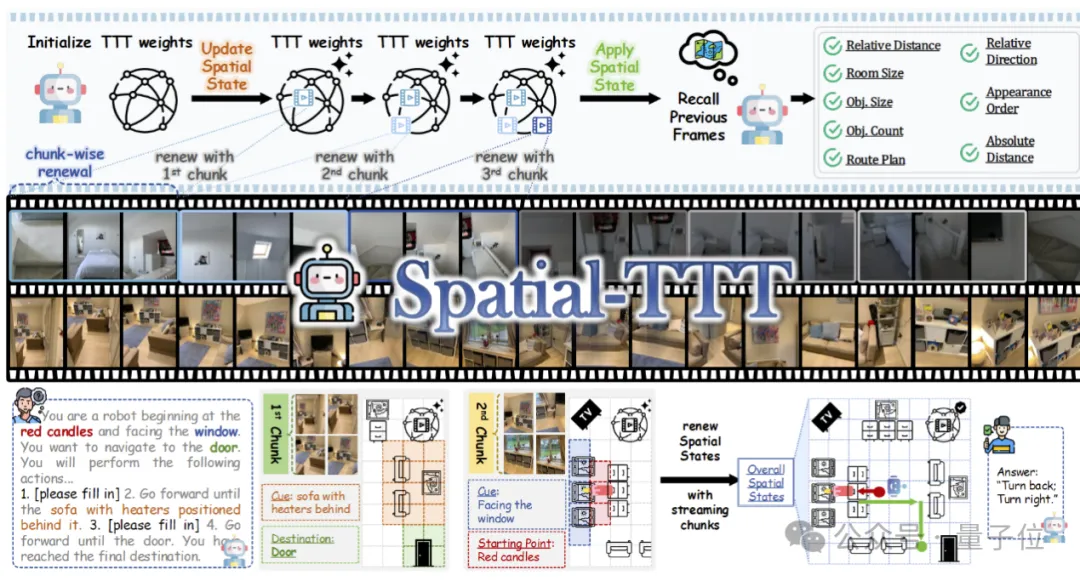
入选ECCV 2026!清华开源空间模型打败Gemini:真正的空间智能是在世界变化中持续学习
入选ECCV 2026!清华联合腾讯混元提出开源空间模型GEM,在复杂动态场景空间推理中全面超越Gemini,证明真正的空间智能需要在世界变化中持续学习。
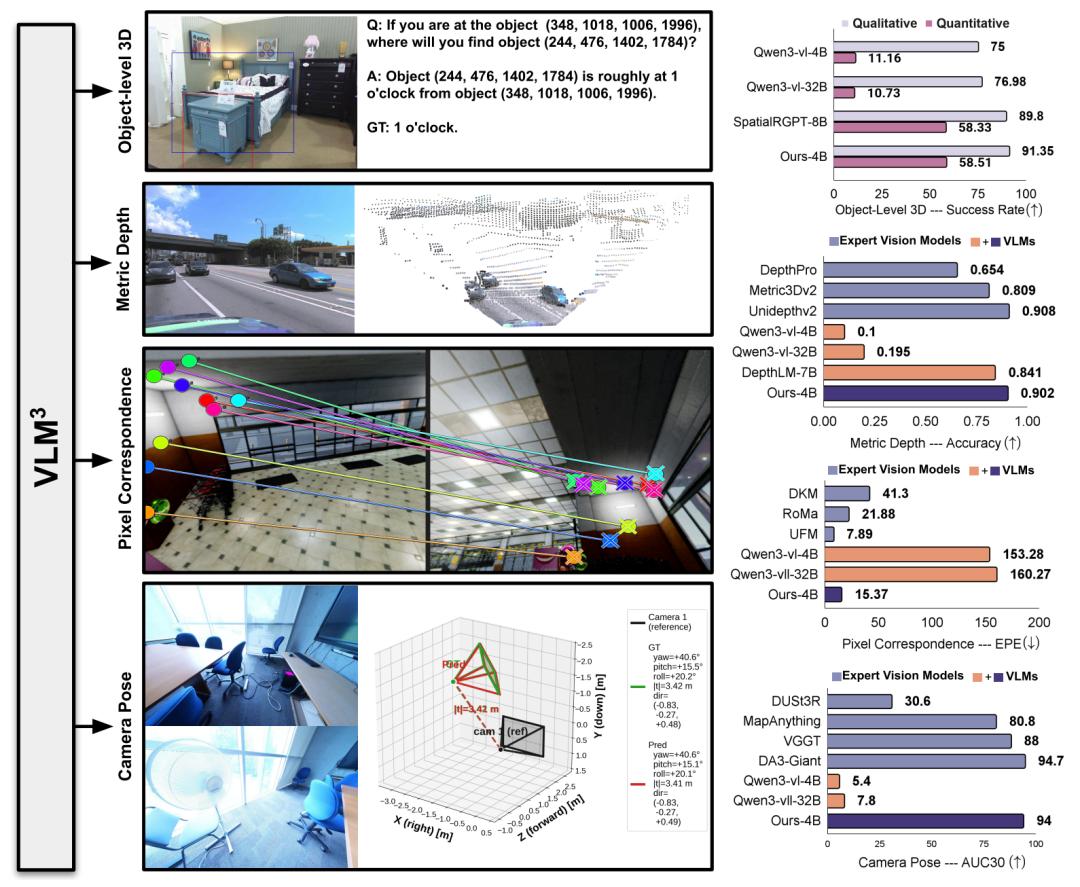
深度估计准确率冲上0.9,Meta提出VLM³,论证视觉模型天生会学3D,以Qwen3-VL-4B为基础实现多任务的统一建模
Meta与普林斯顿大学联合提出VLM³,证明标准视觉语言模型天生具备3D理解能力,基于Qwen3-VL-4B实现深度估计、像素匹配等多任务统一建模,深度估计准确率突破0.9。
π0.7发布,VLA押出了机器人的GPT-3时刻
π0.7发布标志着具身智能在多模态学习与泛化能力上的重大突破,VLA技术首次实现从训练数据中“涌现”新能力。

SceneXplain
SceneXplain 是一个强大的图像视频理解工具,能为视觉内容生成详细字幕和摘要,增强可访问性与叙事能力。

Qwen2-VL
Qwen2-VL是阿里开源的先进视觉语言大模型,融合视觉与语言理解能力。