入选ECCV 2026!清华开源空间模型打败Gemini:真正的空间智能是在世界变化中持续学习

自动驾驶场景下,模型可能产生物理幻觉;长时间推演中,几何一致性逐渐崩坏;极端corner case里,它给出过度自信的错误预测。当AI试图理解与在动态变化的世界博弈时,现有视觉语言模型像“近视眼”,能看清物体却把握不住方向、深度和空间关系。正是为了攻克这一难题而诞生的GEM,它代表用真实深度图训练,让AI在变化的世界中持续变化的世界中掌握的空间智能。
三项核心缺陷倒逼:空间智能为何“知易行难”
现有视觉语言模型(VLM)能看图说话,却常犯低级错。例如在机器人在抓取时撞倒向错误方向,或在导航时针对同一场景已变化却照搬旧规则。这源于三个痛点:
- 物理幻觉严重:模型描述画面位置,但实际构图,却无法理解“桌子前面”这类空间关系。
- 几何一致性差:面对连续视频帧,深度估计几何结构随时间发散,导致规划崩溃。
- 过度自信错误过度自信**:在罕见场景怪(corner case)下,模型给出看似合理、位置都错的预测,却毫不“察觉”。
这些缺陷根源在于传统VLM训练偏重语义标签,忽略了几何建模训练。空间智能若不融入“物体在三维世界如何摆放”的因果逻辑、演化”,就永远是纸上谈兵。
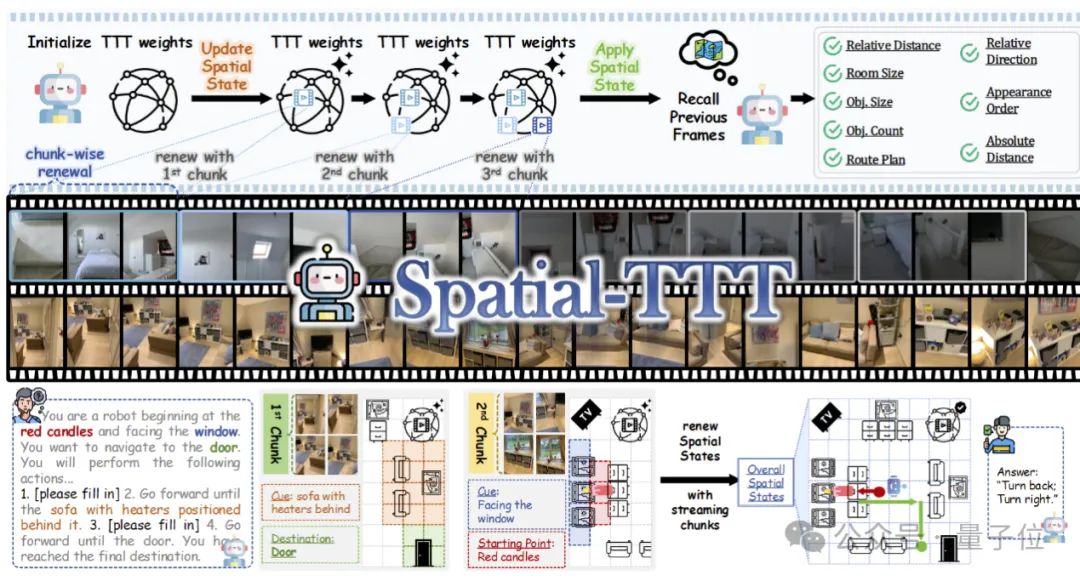
GEM框架:在视觉预训练中植入“深度感知基因”
区别于以往后在模块加载深度信息,GEM从预训练阶段就将深度图生成任务融入语言建模。技术实现分为三大创新:
- 联合训练范式重构:采用视觉语言联合预训练,在训练时要求模型原生输出对应场景的拟深度图,而非仅文本描述;。
- 异构数据对齐**:通过在VLM中间层引入独立的深度头,利用来自RealEstate10等大规模采集多视角数据,使模型学到深度不依赖于显式标。
- 推理微调无缝切换:训练完成的通用基础模型后可在机器人操作、场景快速微调,不牺牲原有语义能力。
简单说,GEM就像给AI配了“双通道”:一只眼看颜色和文字,另一只眼测空间。两眼的信号从一开始就交叉强化。
基准评测、全部领先:Gemini 2.0的空间“盲区”
在空间推理测试中,GEM在多项几何核心任务上大幅抛离“老牌”模型:
- 在目标导航精度上,提升超过15%;在深,误差率同期降低20%以上(对比模型。
- 定位:对物体3D位置估测的中值偏差从米级降至厘米级,直接对应机器人操作成功率。
- 超越Gemini 2.0:在最严苛的空间推理基准套件中,GEM综合得分领先,尤其能准确回答“椅背后方箱子有几”这类涉及立体遮挡和相对方位的复杂查询,而Gemini在同类项目上则频频歧义。
这表明:仅靠文本语义和二维对应不,无法胜任动态交互;GEM通过几何预训练,纠正了此前模型在“变化”场景中的滞后。
开源筑基:面向持续学习,让空间智能“实时进化”
GEM已在GitHub、Hugging Face全面开源,配合高度集成的数据集和训练代码与训练工具。核心价值不在“一次输出”,而在”系统具备根据世界状态不断自我更新——闭源模型无法做到的。
中国具身智能大会(CEAI2026)也在同频推动,大会“智驱万物,具汇江淮”主题下,众多与GEM同类的前沿世界模型将加速落地。正如专家指出:未来的世界模型必须以预测和变化的环境共同学习,而GEM首个示范能姿态建立了开放的技术路径。