传统媒体开始向AI“谈钱”

背景:AI“吃掉”媒体内容,传统媒体警觉
随着大模型的迅速发展,训练数据成为关键资源。AI公司往往通过爬虫抓取互联网内容进行训练,其中大量包含了传统媒体的原创文章。财经类媒体尤为敏感,因为它们的内容具有高专业性、高时效性和高价值,常被用于金融信息分析和投资决策参考。
这些内容一旦被AI“消化”,用户可能不再访问原文链接,而是直接通过AI问答获得摘要信息。这意味着传统媒体不仅失去了流量,还失去了品牌曝光和广告收益。
行动:划清边界,拒绝无偿使用
2025年,包括《证券时报》《上海证券报》《证券日报》《中国基金报》《21世纪经济报道》、第一财经集团、《每日经济新闻》在内的七家主流财经媒体,联合发布声明:
- 未经书面许可,不得将原创内容用于机器学习、数据挖掘、大模型训练、文字转音视频等AI应用场景。
此举标志着传统媒体开始从“被动防御”转向“主动定义规则”,试图在AI训练数据的使用边界上发出自己的声音。
冲突升级:从平台之争到AI“原料”之争
在今日头条、微信、微博等算法平台崛起时,传统媒体失去了“入口”和“分发权”,但内容仍保留在原平台,用户点击、广告分成等机制依然存在。
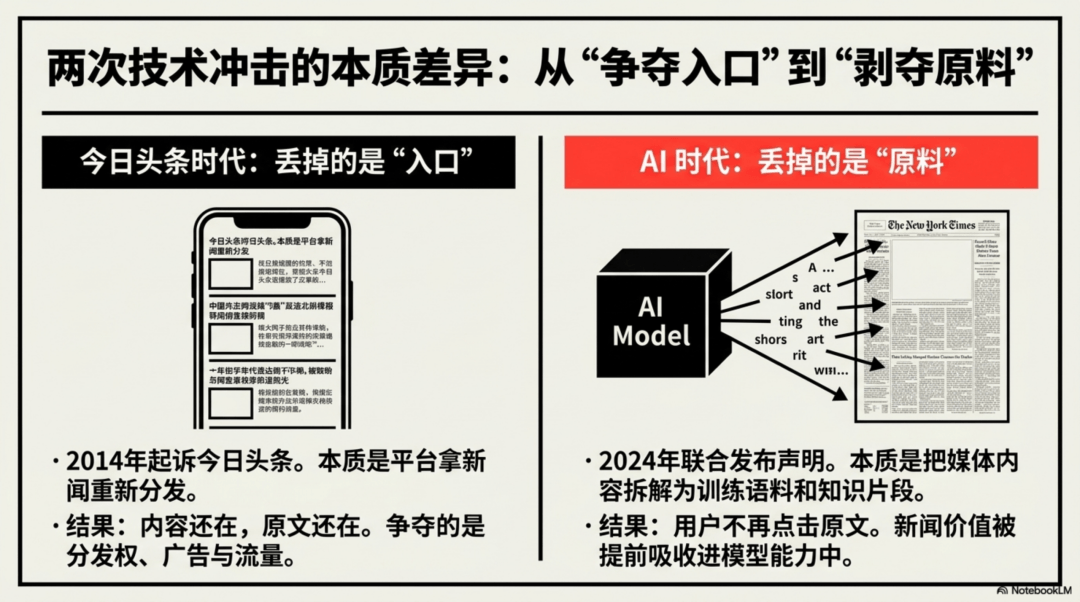
但AI时代不同:
- 大模型不是“转载”或“推荐”,而是将内容拆解为语料、知识片段、问答素材等。
- AI通过训练吸收这些内容后,直接以摘要、分析、问答等形式输出,用户无需再访问原文。
这绕开了传统媒体的商业闭环:订阅、广告、授权转载、品牌价值等。财经媒体尤其受损,因为其内容长期沉淀为结构化数据库,对AI训练极具价值。
国际先例:版权诉讼与授权合作并行
海外媒体早已开始应对AI对内容的使用:
- 《纽约时报》在2023年起诉OpenAI和微软,指控其未经许可使用大量文章训练AI。
- 虽然部分请求被驳回,但版权主张仍在推进。
- 同时,AP(美联社)、《金融时报》、News Corp等媒体与OpenAI达成授权协议,允许其使用历史内容进行训练。
这些案例为国内媒体提供了重要参考,即:
- 版权维权与商业合作并不冲突。
- 媒体可以通过授权机制,将内容转化为AI公司愿意付费的数据资产。
未来路径:传统媒体如何变现内容资产
传统媒体意识到,单纯“禁止”无法阻止AI的发展,但可以通过新商业模式重新找回议价权。可能的发展路径包括:
1. 优质内容授权
媒体将历史稿件、实时新闻、行业数据库等打包,作为高质量训练语料进行授权,形成“AI数据产品”。
2. 可信信源合作
大模型需要减少“幻觉”、提升准确性,权威媒体的信源因此具有更高价值。AI公司可能愿意付费获取可信内容源。
3. AI搜索与问答分成
未来用户可能通过AI助手获取新闻摘要或行业分析。若AI答案调用了媒体内容,是否需要导流、展示来源、分账,将成为新规则谈判点。
4. 内容资产证券化
财经媒体可能率先推动内容资产的结构化、标准化、可审计化,使内容库成为可定价、可授权、可持续更新的数据资产。
挑战与隐忧:从“内容发布者”到“数据资产持有者”
传统媒体要成功转型为“数据资产持有者”,还需面对多重挑战:
- 数据标准化困难:如何将新闻内容转化为机器可读、可训练的数据格式,仍需技术与流程改造。
- 平台强势地位未变:如知乎、小红书等内容平台,早已被大模型“训练”,但并未获得相应收益。
- 用户习惯难以扭转:即便AI使用了媒体内容,用户仍可能更习惯在AI平台获取信息,而非返回原始媒体网站。
- 授权市场尚未成熟:目前尚未形成统一的AI内容授权机制,媒体间也难达成一致,导致议价能力分散。
结语:AI时代,传统媒体不再沉默
传统媒体过去在多个平台变迁中逐渐失去分发权和流量入口,但在AI时代,它们开始意识到自身内容不仅是信息,更是“数据资产”。
这次集体发声,不是终点,而是媒体在新内容生态中重新定义自身价值的起点。它们要做的,不只是“写新闻”,更是“卖知识”。