统一VLA范式,港科大开源StarVLA乐高式架构,复现成本大幅降低

背景:VLA研究的复杂性与高门槛
视觉-语言-动作(Vision-Language-Action, VLA)模型作为连接感知、语义理解和行为决策的关键技术,近年来在机器人控制、智能助手等领域取得显著进展。然而,当前VLA研究面临两个主要问题:一是模型架构多样化导致的复现难度大;二是训练成本高昂,依赖大量算力资源。这些问题阻碍了该领域的快速迭代和广泛应用。
StarVLA的创新:乐高式模块化架构
港科大团队推出的StarVLA项目,提出了一种Backbone-Action Head的“乐高式”统一架构设计:
- Backbone:负责统一处理视觉与语言输入,提取跨模态特征。
- Action Head:解耦动作生成模块,可灵活适配不同任务和动作空间。
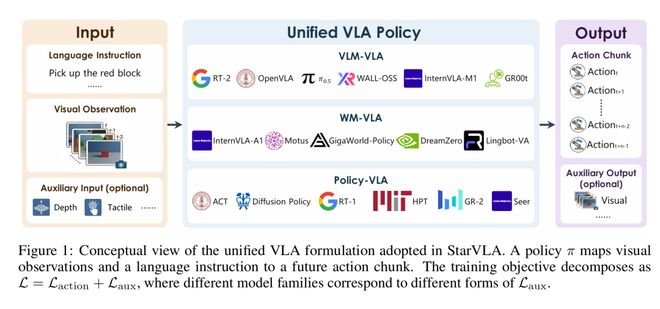
这种模块化设计允许研究人员在不同组件之间自由组合、替换,显著降低了从头构建VLA模型的复杂性。相比传统方法,StarVLA避免了算力堆砌和冗余开发,使得复现和部署更加高效。
技术实现与开源策略
StarVLA的核心在于系统抽象层面的统一设计,而非追求性能榜单的提升。其开源策略体现了教育和研究导向:
- 提供清晰的模块接口,便于扩展和定制。
- 支持主流视觉和语言模型作为Backbone。
- Action Head设计兼容多种下游任务,如视觉问答、图像描述生成和机器人指令执行。
通过这种方式,StarVLA为研究人员提供了一种轻量、灵活的开发范式,有助于推动VLA模型在学术界和工业界的普及。
影响:推动VLA领域标准化与普及
StarVLA的发布有望在多个方面产生深远影响:
- 降低复现成本:研究人员可以复用已有模块,避免重复开发,节省大量时间与资源。
- 促进跨任务研究:统一架构使得不同任务之间的模型迁移和比较变得更加直接。
- 加速工业应用落地:模块化设计降低了工程实现难度,便于在实际场景中部署VLA模型。
这一项目不仅提升了VLA研究的可访问性,也为未来AI模型的开发提供了新的思路——通过抽象与模块化,实现效率与通用性的平衡。
结语:开源社区与未来方向
StarVLA已在GitHub上开源,社区反馈积极。团队表示将继续完善文档与工具链,推动更多基于该架构的研究成果。未来,港科大计划将该范式扩展至更多模态和任务,探索真正通用的人工智能系统。