硬氪专访

真实世界才是最佳训练场
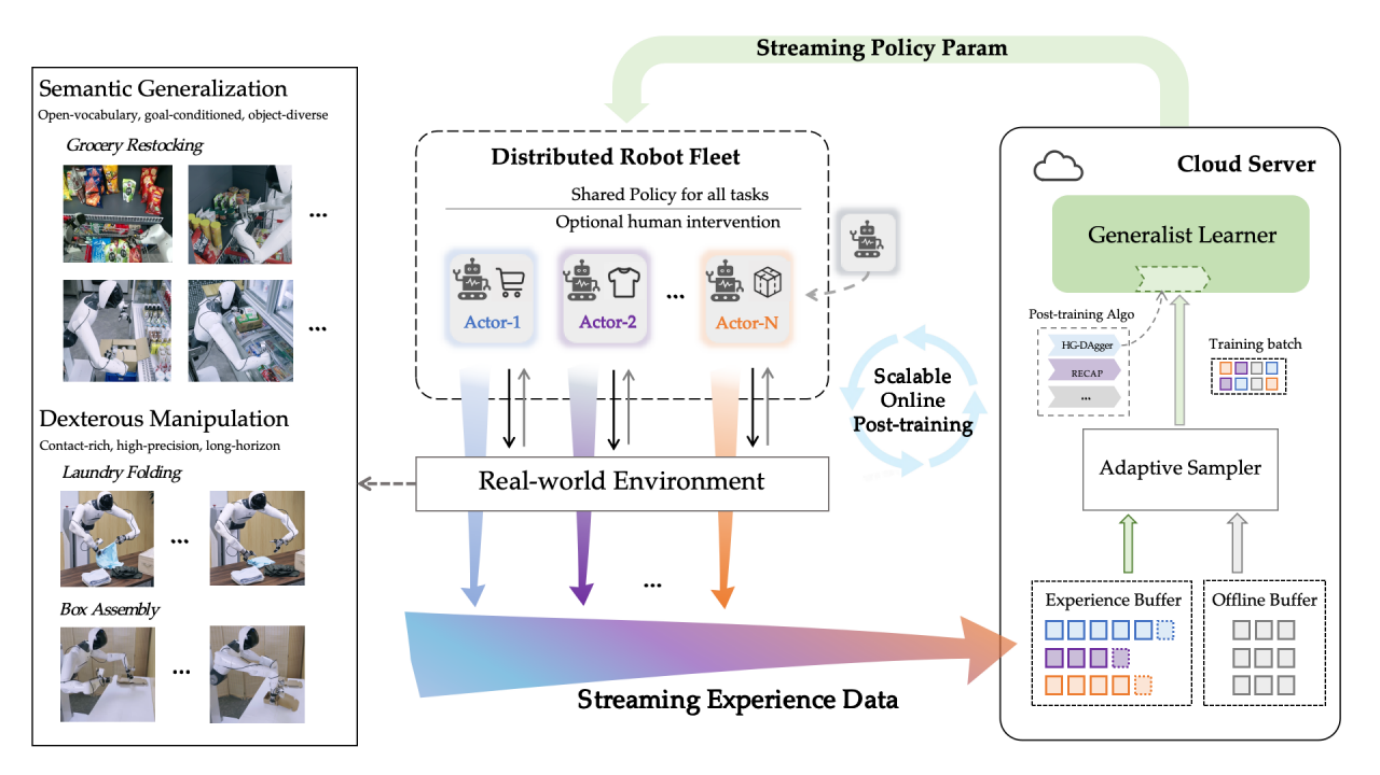
在人工智能从虚拟走向物理的关键转折点,“Scaling Law” 这一在大语言模型领域被验证的规律,正被具身智能行业重新审视。在硬氪的专访中,智元机器人合伙人罗剑岚给出了一个颠覆性的判断:机器人真正的 Scaling Law,一定发生在真实部署的闭环里。他强调,当前大量研究工作依赖仿真数据或有限的实验室环境,但这无法模拟真实世界中复杂的物理交互、动态变化以及偶然事件。只有让机器人在真实的工业产线、家庭服务、物流仓储等场景中“活着”干活,它们才能暴露“没见过、没练过”的盲区,从而驱动模型迭代。罗剑岚直言,一个能长期稳定运行的工程系统——数据回流、模型后训练、策略更新——远比在实验室里跑通一个漂亮 Demo 更有价值。
从“数十台”到“数量级”的飞越
要实现上述闭环,核心前提是足够规模的机器人部署量。罗剑岚透露了一个雄心勃勃的计划:2026年,智元将部署比现有数量高出几个数量级的通用机器人。目前行业普遍处于“数十台”级别的试水阶段,而智元瞄准的是“万台”甚至更高量级。他认为,只有当机器人的“公民”数量足够庞大,才能构建出真正丰富、多元、长尾的真实交互数据池。这些数据不再是遥操作或人工标注的“二手货”,而是由机器人自主行动产生的“原生数据”。这与罗剑岚在另一场行业圆桌上提出的构想一脉相承——用100亿元去构建“世界上最大的自我进化、自我闭环的数据飞轮”。 在他看来,当下还没有一个组织愿意或敢于做这件“难而正确”的事。
一个系统,三种能力
对于具身智能的终极模型形态,罗剑岚反对“单一模型打天下”的简单叙事。他明确表示,最终解决方案是一个“一体的系统”,而非孤立地依赖VLA(视觉-语言-动作)、世界模型或强化学习中的某一个。这个系统需要具备三种核心能力:VLA提供从视觉感知到语言理解再到动作执行的端到端链路;世界模型提供对物理世界的预测、反思与想象能力,在潜在空间做“预演”;强化学习则在真实反馈中不断优化策略。“VLA这个大趋势是对的,但它不见得长成现在这样。” 罗剑岚认为,短期内的VLA存在天然缺陷,而长期来看,这三个模块必须在同一个框架下协同运作,才能让机器人具备“理解后果,规划未来”的智能。
风物长宜放眼量
面对具身智能领域普遍存在的“短期落地难”焦虑,罗剑岚的态度更偏向长期主义。他强调,“短期看是负担,长期看会产生巨大价值。” 在数据采集和模型训练上,他拒绝走捷径。尽管合成数据、仿真数据在成本上极具诱惑力,但他更相信真实物理世界数据的最终统治力。他指出,地球上的“人形机器人居民”太少,不足以支撑起Action First(动作优先)架构的探索,因此必须靠大规模部署来“催生”数据,再反哺模型。在他看来,当下行业对世界模型的狂热讨论,本质上是对“VLA已死”论断的应激反应,但真正的突围之道不在学术黑话的竞赛中,而在那些正在工厂里搬箱子、在仓库里码货的机器人身上——它们每完成一次任务,都在为Scaling Law的涌现贡献一个比特。