“智能体最后的考试”,Fable 5竟然不敌GPT 5.5

智能体最后考试:GPT-5.5逆袭夺魁
被业界称为“AI界最難考卷”的Agents’ Last Exam(ALE)正式放榜。这一基准测试由VentureBeat等媒体重点关注,旨在评估AI模型在真实、长周期且高度复杂的智能体任务中的表现。结果令人意外:原本被广泛看好的Claude Fable 5未能延续统治力,GPT-5.5以24%的通过率微弱领先Fable 5的22%,成功抢回效能榜首。这一结果在社交媒体引发热议,许多观察者惊呼“王者易位”。
24%对22%:险胜背后的能力较量
ALE测试覆盖了从自主规划、工具调用、多步推理到故障排除的全链条智能体能力。GPT-5.5的夺冠并非碾压,而是惊险的反超。根据公开数据,在多个子任务中,两者互有胜负:GPT-5.5在动态环境适应与长程任务连贯性上表现更稳,而Fable 5则在逻辑严谨性与代码生成精度上保持优势。同场对比的Opus 4.8、Gemini 3.1 Pro等模型通过率均低于20%,凸显了TOP2模型的断崖式领先。
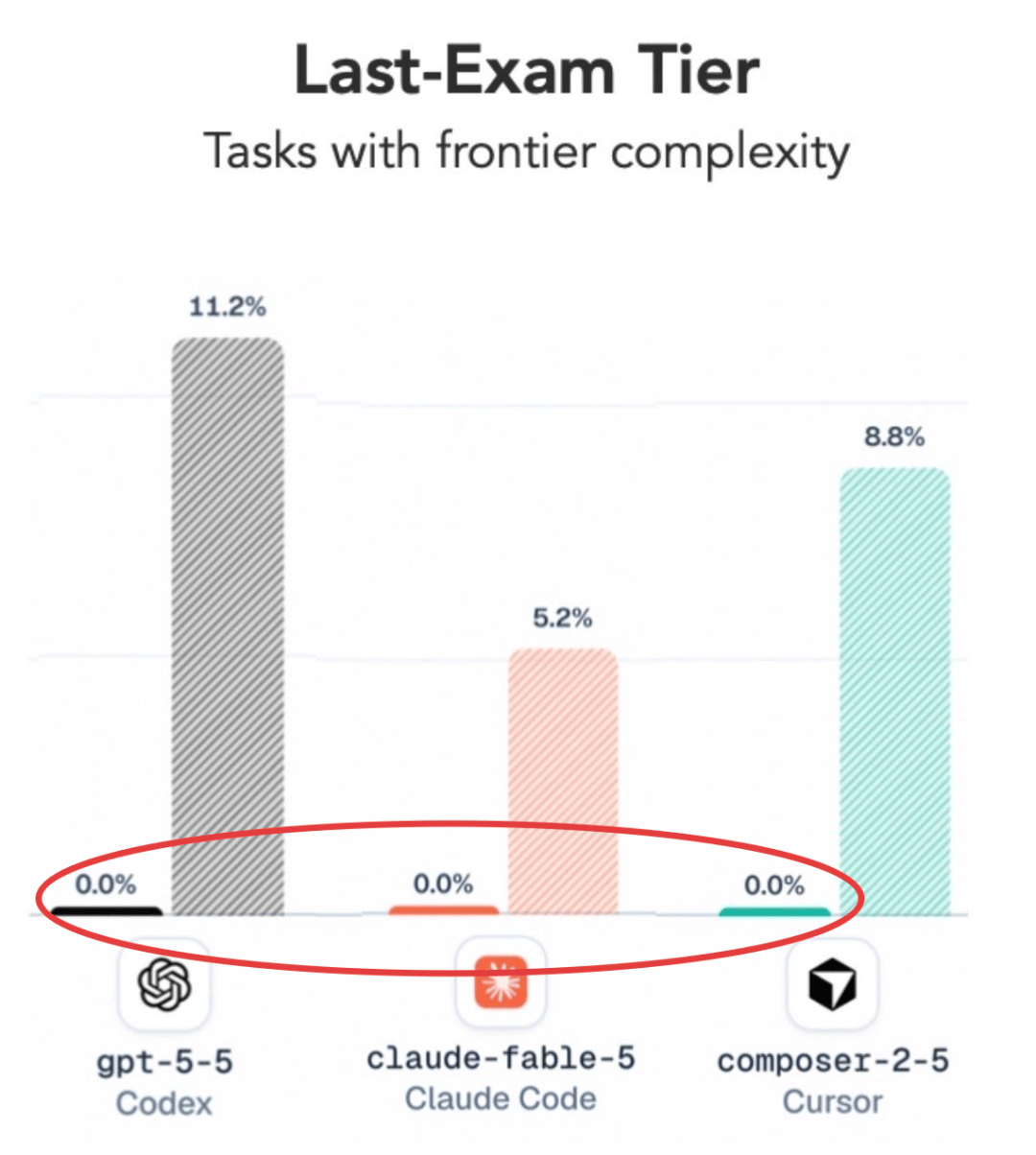
Fable 5虽败犹荣:多领域仍为王者
尽管在ALE上失利,Fable 5在其他权威评测中依然是“全科状元”。在SWE-Bench Pro真实智能体编程榜单上,Fable 5拿下80.3%的高分,远超Opus 4.8(69.2%)与GPT-5.5(58.6%)。在算法设计与创意能力评测中,Fable 5在结构比较(9.4 vs 8.7)、输出质量(9.6 vs 8.6)等维度也明显优于GPT-5.5。此外,支付巨头Stripe曾用Fable 5一天完成5000万行代码的全库迁移——这类超长周期智能体任务正是Fable 5的强项。可以说,ALE的失利更像是“偏科”结果,而非整体实力下滑。
从SWE-Bench到ALE:模型各有千秋
不同基准测试的设计理念决定了模型表现的分化。SWE-Bench Pro侧重单点编程能力与代码修复,这是Fable 5的长项;ALE则更像“智能体高考”,要求模型连续执行大量交叉任务,考验其在高噪音、多目标环境下的决策系统稳定性。GPT-5.5在ALE上的胜出,得益于OpenAI在Agent框架与上下文管理上的持续优化,尤其是对“长文本注意力衰减”问题的改进。正如Anthropic自己的评估:Opus 4.8处于2级向3级(智能体)迈进,Fable 5站稳3级并向4级(创新者)探索——而ALE测试或许正是检验“3级智能体”成熟度的标尺。
竞争加速:AGI前夜的军备竞赛
模型迭代速度令人咋舌:从Opus 4.7到4.8仅用43天,再到Fable 5只有11天。Anthropic在发布Fable 5时同时警告,其底层模型Mythos 5已具备CB-1级(生物/化学武器合成指导能力),导致公司不得不实施30天全量数据留存与静默安全路由。OpenAI则一边让GPT-5.5在ALE上夺冠,一边加速推进下一代模型。这场“你追我赶”的竞争,本质上是对AI产业分工主导权的争夺——最顶尖的智能体能力,正从通用对话转向生产力战略物资,定向输送给基建、科研与B端战场。ALE测试的逆转,不过是这场AGI军备竞赛中的一个小高潮。