阿里最强全模态模型登场,实测看懂50分钟《老友记》,全球评测215项SOTA

背景与行业趋势
近年来,随着大语言模型(LLMs)的快速发展,多模态学习逐渐成为人工智能研究的重点。传统语言模型在理解文本信息方面表现优异,但面对图文、音视频等复杂数据时,仍存在诸多限制。阿里此次发布的全新全模态模型,旨在突破这些限制,实现对多种数据形式的统一理解和高效处理。
- 多模态融合:结合视觉、文本、音频等多种信息源,提升模型的综合理解能力。
- 实时处理能力:在50分钟的视频内容理解中表现突出,展示了强大的实时推理能力。
- SOTA突破:在全球215项评测中刷新最佳成绩,标志着阿里在AI领域又一重大进展。
模型技术亮点
阿里此次发布的模型不仅在模态融合上做了深度优化,还采用了多项前沿技术,以确保其在复杂任务中的高性能表现。
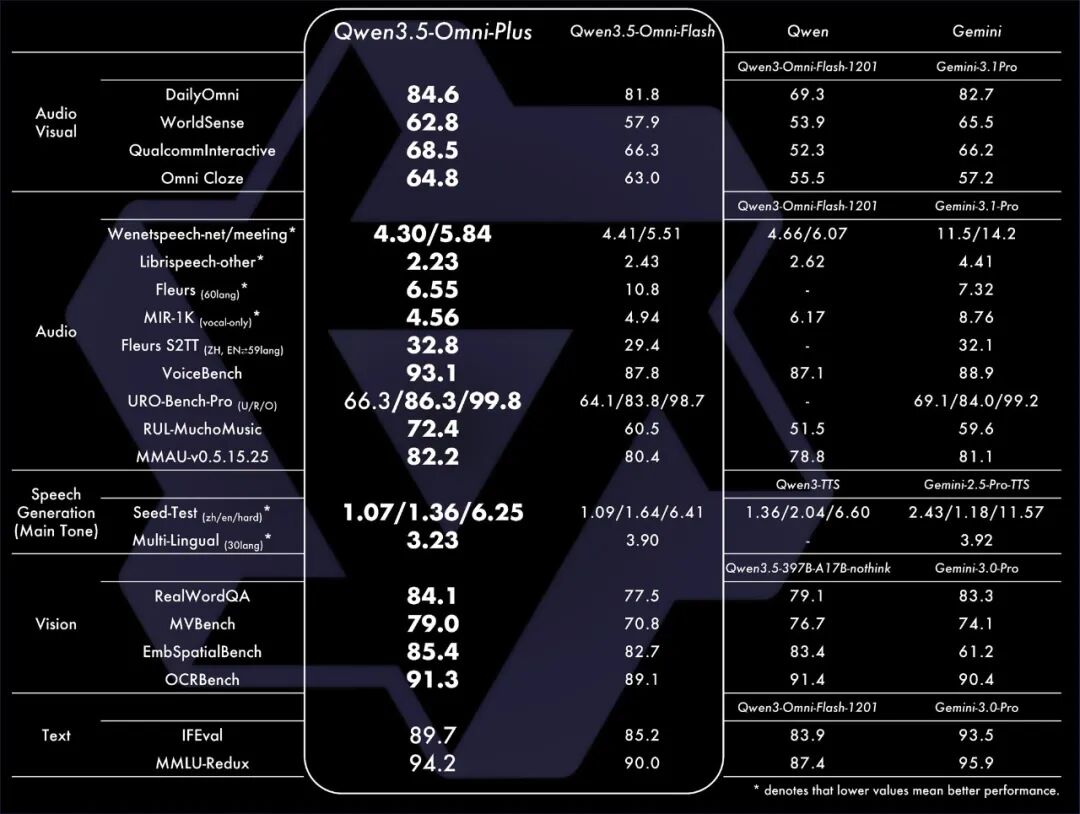
- 统一模态编码架构:模型基于Transformer架构,针对不同模态进行结构适配,实现了跨模态信息的高效对齐。
- 动态注意力机制:在视频理解任务中,模型能够动态识别关键帧和对话内容,确保信息不丢失且处理效率高。
- 知识蒸馏与合成数据增强:通过引入知识蒸馏策略和基于合成数据的训练,模型在缺乏标注数据的情况下仍保持高性能。
- 大规模回填翻译与多阶段预训练:借鉴机器翻译中的策略,增强了模型对语言结构的深层理解,尤其在跨模态语义对齐方面表现卓越。
实测表现与能力展示
在实际测试中,该模型展示了令人印象深刻的理解与推理能力。以50分钟的《老友记》视频为例,模型不仅能够准确识别角色对话、场景变化,还能理解剧情发展与人物情绪变化。
-
视频内容解析:
- 识别关键人物与对话内容。
- 分析角色关系与情节线索。
- 对话生成与上下文理解保持连贯。
-
跨模态任务处理:
- 视频+文本问答准确率高。
- 多语言翻译能力稳定,支持中英日等主流语言。
- 图像描述生成自然流畅,细节还原度高。
应用前景与行业影响
随着该模型的发布,阿里在多模态AI领域的领先地位进一步巩固,其潜在应用场景也极为广泛。
- 智能客服与虚拟助手:可理解用户上传的图文、语音信息,提供更自然、精准的服务。
- 内容创作与编辑:支持视频、图文自动摘要、内容生成,助力内容创作者提升效率。
- 教育与医疗:结合视频与文本分析,辅助教学、病情记录解读等任务。
- 智能翻译系统:提升跨语言理解与翻译质量,推动全球化信息无障碍交流。
总结与未来展望
阿里此次推出的全模态模型不仅在技术上实现突破,更在实际应用层面展现出巨大潜力。未来,该模型有望被部署在更多实际场景中,推动AI技术从单一模态走向真正意义上的“通感”理解。
- 持续优化模型效率:降低部署成本,适配更多硬件环境。
- 扩展应用场景:在金融、医疗、教育等领域深化落地。
- 构建开发者生态:通过API与开源工具链,吸引更多开发者参与。
该模型的发布也标志着中国AI企业在基础研究与工程落地方面的进一步成熟,或将带动更多企业投入多模态大模型的探索与创新。