别光给Agent加Tool了,它根本选不明白!复旦×通义提出全新CUA训练范式

Agent只会加Tool?选不明白工具才是真痛点
当前多模态Agent的标配是“模型+一堆工具”,但实际落地时经常出现一个尴尬局面:模型把工具列表从头到尾试一遍,要么频繁调用无关工具造成无效交互,要么在GUI页面瞎点一气。问题的根源不在工具数量,而在于模型缺少“什么时候该用、什么时候不该用”的决策能力。复旦与通义实验室联合提出的CUA(Contextual Utilized Agent)训练范式,恰恰瞄准了这个训练盲区。
复旦×通义亮出新范式:CUA如何让Agent学会“该出手时才出手”
CUA的核心训练目标只有一句话:让模型自主区分三种操作场景。一是走GUI——当界面元素可直接完成目标时,模型优先通过视觉-动作路径操作UI。二是切Tool——遇到界面无法完成的调用(如计算、查数据库),模型会识别需求并选择对应API/工具。三是不动——当当前状态已达成目标、或工具调用会带来副作用时,模型学会克制,直接输出最终结果。
这种三元决策训练不同于传统“工具越多越好”的堆料逻辑,而是把“选择合适的操作路径”本身作为模型的推理任务来优化。
从GUI到Tool再到“不动”:一个统一的训练目标
传统Agent训练通常让模型记住工具接口定义,但CUA在训练中引入统一的决策流:视觉感知界面状态→推理当前任务阶段→判断下一步应执行GUI动作、调用工具还是保持静止。通过混合GUI轨迹、工具调用范例和“不动”示例,模型学会了在连续步骤中动态切换行为模式,而不是机械地执行预设工具链。
具体训练上,CUA采用了多模态指令微调加自洽性奖励,让模型在决策时不仅考虑当前步的收益,还要评估对后续步骤的影响。这避免了模型贪图“立即调用工具”而破坏整体任务流程的短视行为。
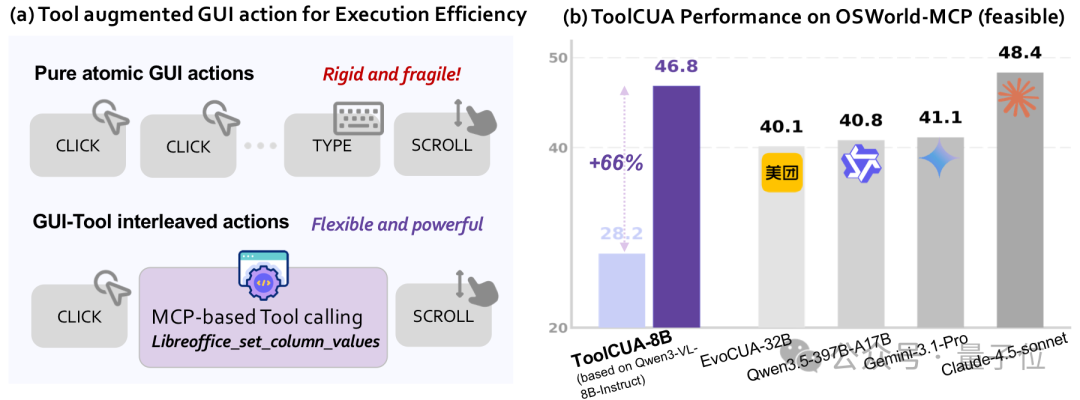
实测结果能打:ToolCUA-8B拿下46.85%准确率
基于CUA范式训练的8B参数模型ToolCUA-8B,在OSWorld-MCP基准测试中取得了46.85%的准确率。这个成绩的意义在于:它证明了小型模型通过合理的训练范式而不是无限堆算力,也能在复杂任务中做出聪明的工具选择决策。与同参数级别传统Agent对比,ToolCUA-8B在减少无效工具调用、提升任务完成连贯性方面表现更优,尤其擅长处理“GUI和工具混合使用”的典型办公自动化场景。